- A+
知识图谱(Knowledge Graph)是当前学术界和企业界的研究热点。中文知识图谱的构建对中文信息处理和中文信息检索具有重要的价值。中国中文信息学会(CIPS)邀请了有约10家从事知识图谱研究和实践的著名高校、研究机构和企业的专家及学者有意参与并发表演讲,下面就是第一届全国中文知识图谱研讨会的学习笔记。
会议介绍地址和PPT下载链接:http://www.cipsc.org.cn/kg1/

第一篇以现有百度知心和搜狗知立方为主,其中文章目录如下所示:
一.知识图谱相关引入介绍
二.NLP Techniques in Knowledge Graph —— 百度知心
三.面向知识图谱的搜索技术 —— 搜狗知立方
PS:希望大家看原文PDF,因为由于我也还在学习过程中,本人理解程度不够;同时有没有现场听这个讲座,所以很多具体实现方法和过程都无法表述。
下载地址:http://download.csdn.net/detail/eastmount/9255871
一. 知识图谱相关引入介绍
在介绍会议内容之前,我准备先给大家介绍下知识图谱的基础知识。前面我也介绍过很多知识图谱相关的文章,这里主要阅读华南理工大学华芳槐的博士论文《基于多种数据源的中文知识图谱构建方法研究》,给大家讲解知识图谱的内容及发展历史。
(一).为什么引入知识图谱呢?
随着信息的爆炸式增长,人们很难从海量信息中找到真实需要的信息。搜索引擎正是在这种情况下应运而生,其原理是:
1.通过爬虫从互联网中采集信息,通过建立基于关键词的倒排索引,为用户提供信息检索服务;
2.用户通过使用关键词描述自己的查询意图,搜索引擎依据一定的排序算法,把符合查询条件的信息依序(打分)呈现给用户。
搜索引擎的出现,在一定程度上解决了用户从互联网中获取信息的难题,但由于它们是基于关键词或字符串的,并没有对查询的目标(通常为网页)和用户的查询输入进行理解。
因此,它们在搜索准确度方面存在明显的缺陷,即由于HTML形式的网页缺乏语义,难以被计算机理解。
(二).语义Web和本体的概念
为解决互联网信息的语义问题,2008年Tim Berners-Lee等人提出了下一代互联网——语义网(The Semantic Web)的概念。在语义Web中,所有的信息都具备一定的结构,这些结构的语义通常使用本体(Ontology)来描述。
当信息结构化并且具备语义后,计算机就能理解其含义了,此时用户再进行检索时,搜索引擎在理解互联网中信息含义的基础上,寻找用户真实需要的信息。由于互联网中信息的含义是由本体来描述的,故本体的构建在很大程度上决定了语义Web的发展。
本体(Ontology)描述了特定领域(领域本体)或所有领域(通用本体)中的概念以及概念之间的关联关系,并且这些概念和关系是明确的、被共同认可的。通常,本体中主要包括概念、概念的其他称谓(即同义关系)、概念之间的上下位关系、概念的属性关系(分为对象属性和数值属性)、属性的定义域(Domain)和值域(Range),以及在这些内容上的公理、约束等。
(三).知识图谱发展历程
随着互联网中用户生成内容(User Generated Content, UGC)和开放链接数据(Linked Open Data, LOD)等大量RDF(Resource Description Framework)数据被发布。互联网又逐步从仅包含网页与网页之间超链接的文档万维网(Web of Document)转变为包含大量描述各种实体和实体之间丰富关系的数据万维网(Web of Data)。
在此背景下,知识图谱(Knowledge Graph)正式被Google于2012年5月提出,其目标在于改善搜索结果,描述真实世界中存在的各种实体和概念,以及这些实体、概念之间的关联关系。紧随其后,国内外的其它互联网搜索引擎公司也纷纷构建了自己的知识图谱,如微软的Probase、搜狗的知立方、百度的知心。知识图谱在语义搜索、智能问答、数据挖掘、数字图书馆、推荐系统等领域有着广泛的应用。
下图是搜狗知立方“姚明”的关系图:
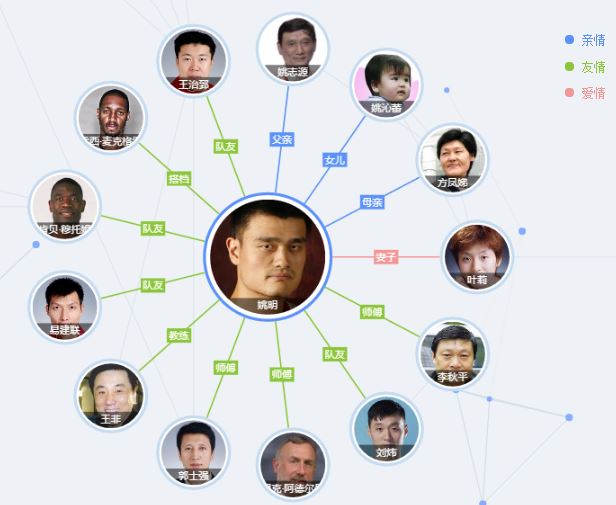
谷歌S. Amit的论文《Introducing the Knowledge Graph: Things, Not Strings》
阿米特·辛格尔博士通过“The world is not made of strings, but is made of things”这句话来介绍他们的知识图谱的,此处的“thing”是和传统的互联网上的网页相比较:知识图谱的目标在于描述真实世界中存在的各种实体和概念,以及这些实体、概念之间的关联关系。
知识图谱和本体之间又存在什么区别呢?
知识图谱并不是本体的替代品,相反,它是在本体的基础上进行了丰富和扩充,这种扩充主要体现在实体(Entity)层面;本体中突出和强调的是概念以及概念之间的关联关系,它描述了知识图谱的数据模式(Schema),即为知识图谱构建数据模式相当于为其构建本体;而知识图谱则是在本体的基础上,增加了更加丰富的关于实体的信息。
知识图谱可以看成是一张巨大的图,图中的节点表示实体或概念,而图中的边则构成关系。在知识图谱中,每个实体和概念都使用一个全局唯一的确定ID来标识,这个ID对应目标的标识符(identifier);这种做法与一个网页有一个对应的URL、数据库中的主键相似。
同本体结构一样,知识图谱中的概念与概念之间也存在各种关联关系;同时,知识图谱中的实体之间也存在这同样的关系。实体可以拥有属性,用于刻画实体的内在特性,每个属性都是以“<属性,属性值>对(Attribute-Value Pair, AVP)”的方式来表示的。
(四).知识图谱举例
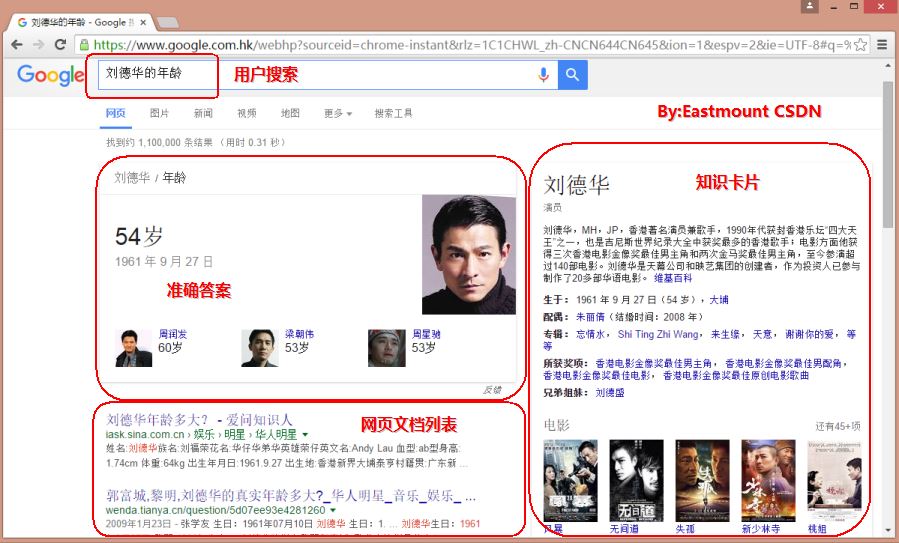
总之,知识图谱的出现进一步敲开了语义搜索的大门,搜索引擎提供的已经不是通向答案的链接,还有答案本身。下图展示Google搜索结果的快照,当用户搜索“刘德华的年龄”时,其结果包括:
1.列出了相关的网页文档检索结果;
2.在网页文档的上方给出了搜索的直接精确答案“54岁”;
3.并且列出了相关的人物“梁朝伟”、“周润发”以及他们各自的年龄;
4.同时在右侧以知识卡片(Knowledge Card)的形式列出了“刘德华”的相关信息,包括:出生年月、出生地点、身高、相关的电影、专辑等。
知识卡片为用户所输入的查询条件中所包含的实体或搜索返回的答案提供详细的结构化信息,是特定于查询(Query Specific)的知识图谱。
这些检索结果看似简单,但这些场景背后蕴含着极其丰富的信息:
1.首先,搜索引擎需要知道用户输入中的“刘德华”代表的是一个人;
2.其次,需要同时明白“年龄”一词所代表什么含义;
3.最后,还需要在后台有丰富的知识图谱数据的支撑,才能回答用户问题。
同时,知识图谱还在其他方面为搜索引擎的智能化提供了可能,辛格尔博士指出:搜索引擎需要在答案、对话和预测三个主要功能上进行改进。另外,知识图谱在智能问题、知识工程、数据挖掘和数字图书馆等领域也具有广泛的意义。
按照覆盖面,知识图谱可以分为:
1.通用知识图谱
目前已经发布的知识图谱都是通用知识图谱,它强调的是广度,因而强调更多的是实体,很难生成完整的全局性的本体层的统一管理;另外,通用知识图谱主要应用于搜索等业务,对准确度要求不是很高。
2.行业知识图谱
行业知识图谱对准确度要求更高,通常用于辅助各种复杂的分析应用或决策支持;严格与丰富的数据模式,行业知识图谱中的实体通常属性多且具有行业意义;目标对象需要考虑各种级别的人员,不同人员对应的操作和业务场景不同。
本体构建:人工构建方式、自动构建方式和半自动构建方式
二. NLP Techniques in Knowledge Graph —— 百度知心
主题和主讲人:百度知识图谱中的NLP技术——赵世奇(百度)
(一).Baidu Knowledge Graph
百度知心访问链接:http://tupu.baidu.com/xiaoyuan/
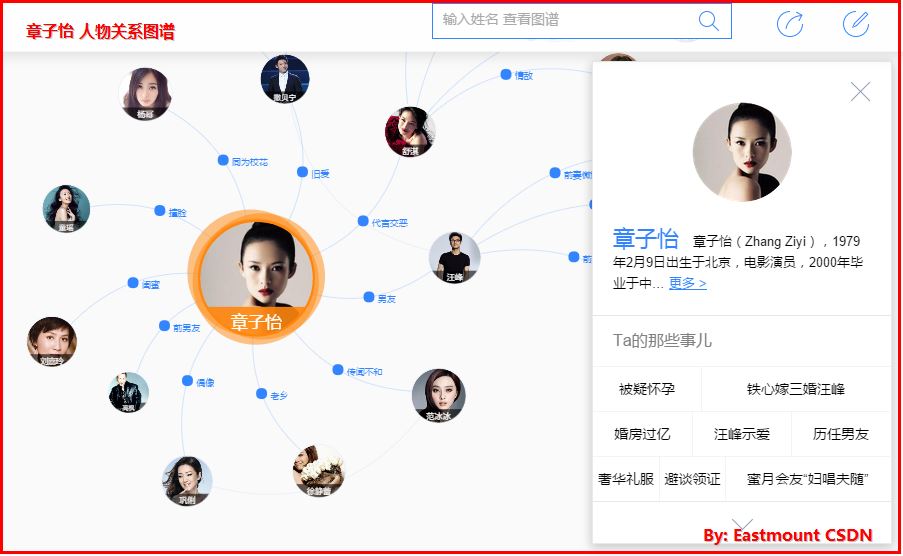
其中百度知识图谱“章子怡”人物关系图谱如下所示:
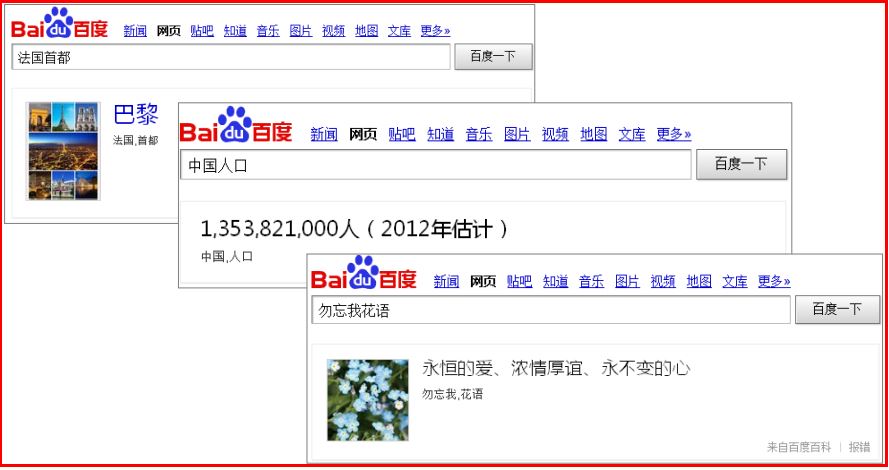
知识图谱与传统搜索引擎相比,它会返回准确的结果(Exact answers),如下:
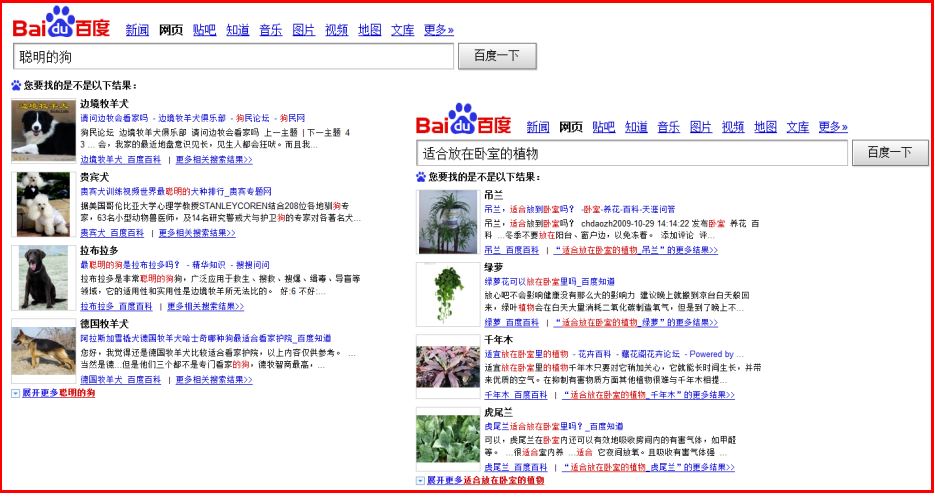
同时知识图谱推荐列表(List Recommendation)如下所示,搜索“适合放在卧室的植物”包括“吊兰、绿萝、千年木”等等。其中Named entities 命名实体、Normal entities 普通实体。
同时,百度知心知识图谱也支持移动端的应用,如下图所示:
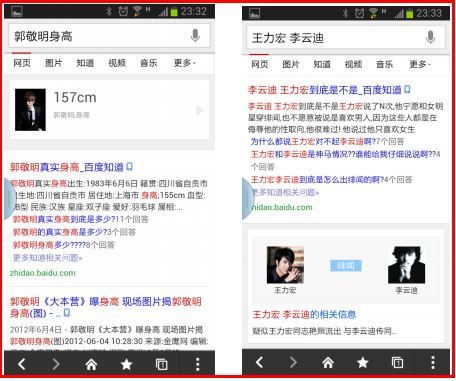
PS:不知道为什么最近使用百度知心搜索的效果不是很好!感觉搜狗知心和google效果更好~
(二).Knowledge Mining
知识挖掘包括:Named entity mining 命名实体挖掘、AVP mining 属性-值对挖掘、Hyponymy learning 上下位学习、Related entity mining 相关实体挖掘。
PS:注意这四个知识点非常重要,尤其是在知识图谱实现中,下图也非常重要。
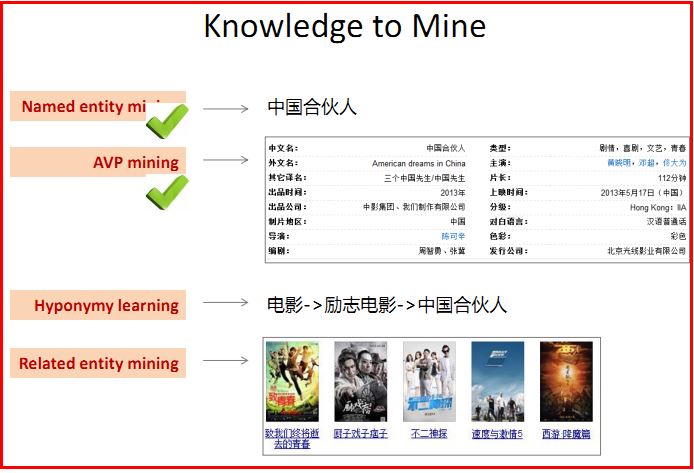
1.命名实体挖掘 Mining Named Entities
传统命名实体(NE)类别:人(Person)、位置(Location)、组织(Organization)
更多对web应用程序有用的新类别:Movie、TV series、music、book、software、computer game
更精细的分类:组织 -> {学校,医院,政府,公司...}
Computer game -> {net game,webpage game,...}
其中web中命名实体的特点包括:新的命名实体迅速崛起,包括软件、游戏和小说;命名实体在网络上的名字是非正式的(informal)
(1)从查询日志(Query Logs)中学习命名实体(NEs)
查询日志中包含了大量的命名实体,大约70%的搜索查询包含了NEs。如下图2007年Pasca论文所示,命名实体能够根据上下文特征(context features)识别。如上下文词“电影、在线观看、影评”等等,识别“中国合伙人”。

Bootstrapping approach
given a hand of seed NEs of a category C
从查询中学习种子的上下文特征,然后使用已经学到的上下文特征来提取C类的新种子实体,使用扩展种子集去扩展上下文特征....
利用查询日志该方法的优点是:它能够覆盖最新出现的命名实体;它的缺点是:旧的或者不受欢迎的命名实体可能会错过。
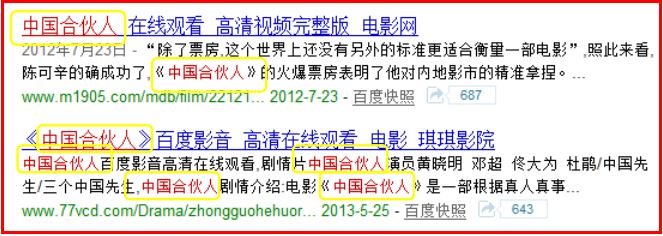
(2)从普通文本中学习命名实体(Learning NEs from Plain Texts)
文字包装器(Text Wrappers)被广泛使用于从纯文本中提取(Extracting)命名实体。例如包装器“电影《[X]》”,“影片[X],导演”,其中[X]表示电影名字。如下图所示:
(3)使用URL文本混合模式(Url-text Hybrid Patterns)学习命名实体
是否有可能只从网页标题(webpage titles)中提取命名实体呢?确实。99%的命名实体都能够在一些网页标题中发现。
Url文本混合模型应该考虑URL约束,简单的文本模式可信的URL链接是足够的,复杂的文本模式需要低质量的URL。其中论文参考下图:
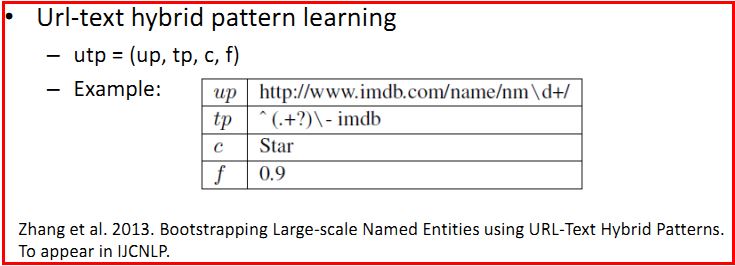
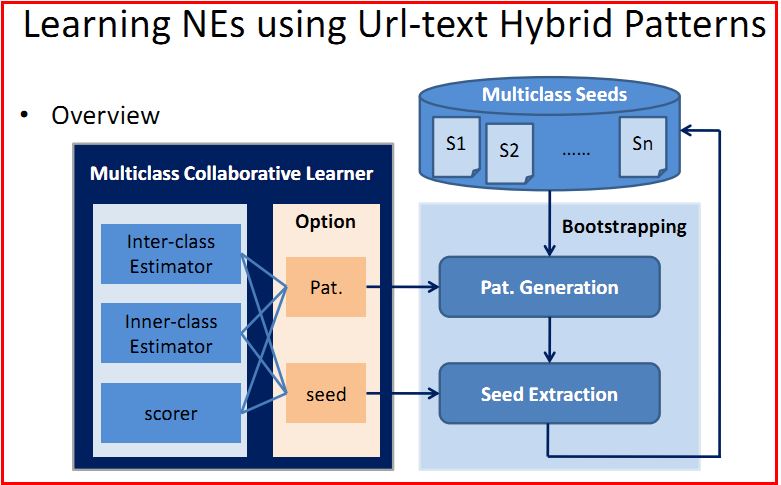
PS:涉及到Multiclass collaborative learning多类协作学习,推荐去看2013年具体的论文,鄙人才疏学浅,能力有限,只能讲些入门介绍。《Bootstrapping Large-scale Named Entities using URL-Text Hybrid Patterns》ZhangZW
2.属性-属性值对挖掘 AVP Mining
AVP英文全称是Attribute Values Pairs。那么,哪里会见到这种AVP数据呢?
在线百科:三大百科 Baidu Baike \ Wikipedia \ Hudong Baike
垂直网站(Vertical websites):IMDB,douban for videos
普通文档网页:从结构化、半结构化(semistructured)和非结构化文本中爬取AVP
(1)挖掘在线百科AVP数据
如下图所示,结构化信息盒infobox准确但不完美,半结构化信息不是足够准确。
PS:结构化数据如数据库中表;非结构化数据像图片、视频、音频无法直接知道它们的内容;半结构化数据如员工的简历,不同人可能建立不同,再如百科Infobox的“属性-值”可能不同,它是结构化数据,但结构变化很大。

(2)挖掘垂直网站AVP数据
下面是从垂直网站中爬取结构化数据或半结构化数据。
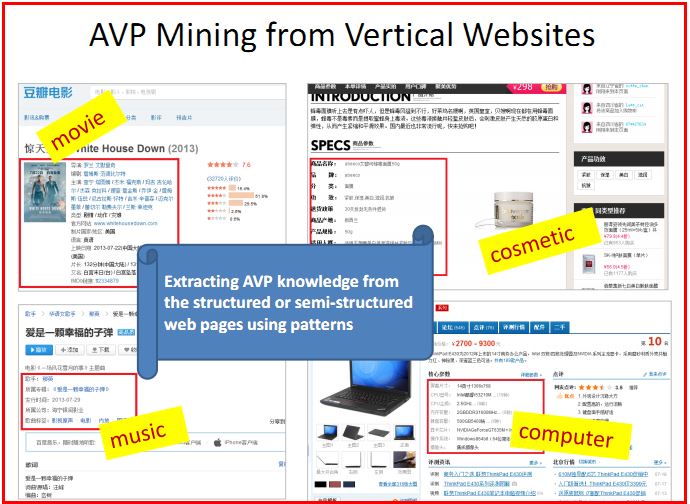
可能会遇到两个问题?
第一个是如何找到相关的垂直网站,如果是寻找流行的网站是容易的,如音乐、电影、小说;但是如果是寻找长尾域(long tail domains)的网站是困难的,如化妆品、杂志。第二个问题是面对众多的数据怎样生成提取模式。

同时,人工模式可以保证很高的准确性,但是工具能够帮助我们更加便利的编辑模式。最后AVP知识需要日常中积累和更新,包括不同时间类别的更新、新网站的加入、无序或网站崩溃需要自动检测或手工处理。
(三).Semantic Computation 语义计算
PS:如果当初参加这个讲座就能叙述清楚了,下面这些表述有些模糊,sorry~
所有模块(modules)都应该是可选的:输入AVP数据决定哪些模块是必需的,模块间的依赖必需遵守。同时,这些模块大部分都是半自动工具(semi-automatic tools)。
下面具体介绍:
1.Cleaning
检测和清除表面错误,包括不可读代码(Unreadable codes)、错误的截断(Erroneous Truncation)、由于挖掘错误引起的错误属性、双字节-单字节替换(Double byte - single byte replacement)、英语字符处理(English character processing)等。
2.Value Type Recognition 值类型识别
自动识别AVP数据所给的属性对应的值类型。其中值类型包括:
Number(数字)、Data/Time(日期/时间)、Entity(实体)、Enumeration(枚举)、Text(default,默认文本)
它可以帮助识别非法属性值和提取候选同义的属性名。
3.Value Normalization 值正常化
Splitting(分词)
E.g., movie_a, movie_b, and movie_c -> movie_a | movie_b | movie_c
Generation
E.g., Chinese zodiac / zodiac: Tiger / The lion (十二生肖/生肖:老虎/狮子)
-> Chinese zodiac: Tiger and zodiac: The lion
Conversion(转换)
E.g., 2.26m -> 226cm
4.Attribute Normalization 属性正常化
Domain-specific problem(特定领域问题)
某些属性被视为同义词只在特定的领域甚至是两个特定的知识源中。
例如“大小(size)”和“屏幕(screen)”在一些手机网站上表示同义词,但不是所有的开放域解释都相同。
分类模型(Classification model)来识别候选同义属性
其中特征包括属性浅层相似特征、相似属性值特征、相似值类型(Value-type)特征和实体值特征。最后评选者从所有候选中选择正确的相似属性对。
5.Knowledge Fusion 知识融合
融合从不同数据来源的知识,关键问题——实体消歧(Entity disambiguation)。
其解决方法是计算两个相同名称实体之间的相似性。一些基本属性可以用来确定实体的身份,如“works of a writer”。其他一些属性只能用来作相似性的特征,如“nationality of a person”(国籍)。
6.Entity Classification 实体分类
为什么需要分类呢?因为一些实体会丢失类别信息;同时不失所有从源数据中挖掘的实体都有类别(category)。解决方法是:通过监督模型训练已知类别的实体和它们的属性-值对;使用结构化数据(AVPs)和非结构化数据(上下文文本)来精确地分类特征。
下面是一些在知识应用层的语义计算模块/方法。主要是具体的应用:
实体消歧用于推理(Entity disambiguation for reasoning)
陈晓旭的演的《红楼梦》
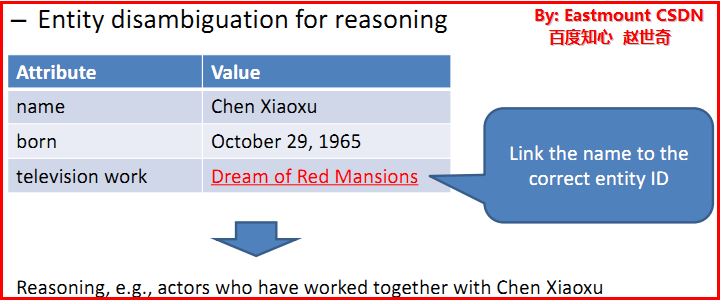
相关实体消歧(Related entity disambiguation)
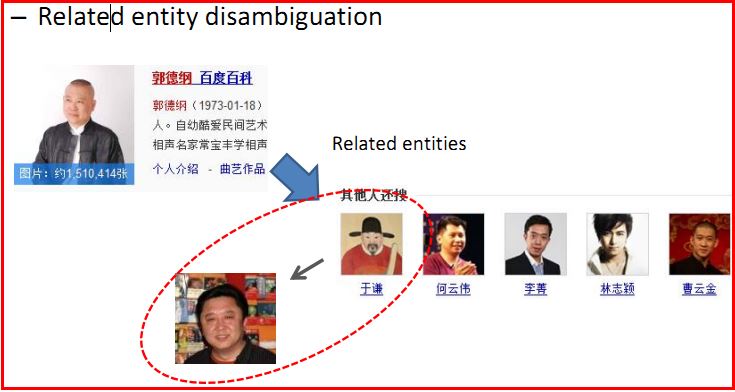
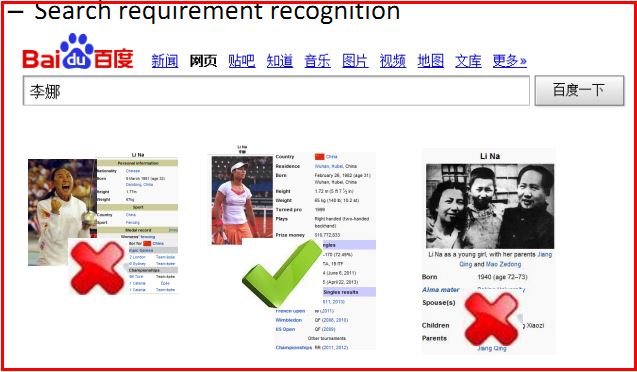
搜索需求识别(Search requirement recognition)
需要识别用户搜索的“李娜”是网球运动员、歌手、舞蹈家还是其他。
其核心问题就是AVP相似计算,包括为不同的属性定义不同的权重、有用属性和无用属性等。

最后总结如下:
1.网络搜索的新趋势:知识搜索、语义搜索、社会化搜索
2.就知识图谱而言,研究语义方面至关重要。知识库的构建和知识搜索都需要语义计算(Knowledge base construction and knowledge search both need semantic computation)。
3.各种网络资源应该被更好的利用:网络语料库、查询记录、UGC数据
三. 面向知识图谱的搜索技术 —— 搜狗知立方
这篇文章主要是搜狗张坤老师分享的知识图谱技术,以前我也讲过搜狗知立方和搜索相关知识,这里就以图片为主简单进行叙述了。参考:搜索引擎和知识图谱那些事
首先简单回顾一下传统的网页搜索技术
其中包括向量模型、Pagerank、根据用户搜索行为发现商业价值和社会价值、Learning to Rank(学习排序),这里就不再详细叙述,我前面有些文章介绍了这些。
参考我的文章:机器学习排序之Learning
to Rank简单介绍
搜索结构发现变化如下所示。
用户需要获取更准确的信息,系统需要时间换取空间,计算替代索引,优质的信息将转化为机器理解的知识,使得这些知识和机器发挥更大作用。
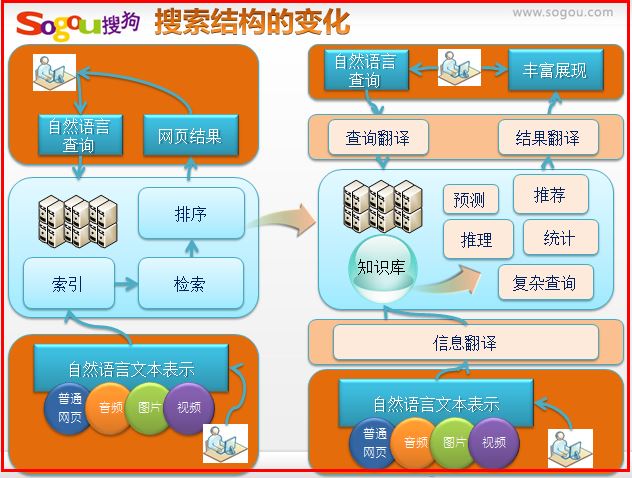
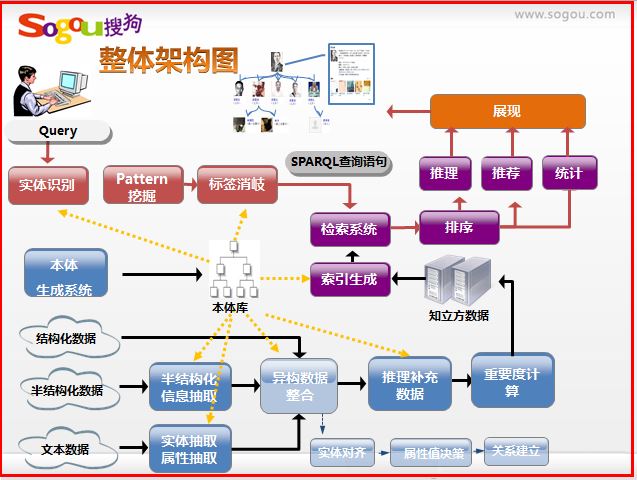
搜狗知立方整体框架图如下所示,其中下部分的实体对齐、属性对齐是我现在研究的部分。主要包括以下部分:
1.本体构建(各类型实体挖掘、属性名称挖掘、编辑系统)
2.实例构建(纯文本属性、实体抽取、半结构化数据抽取)
3.异构数据整合(实体对齐、属性值决策、关系建立)
4.实体重要度计算
5.推理完善数据
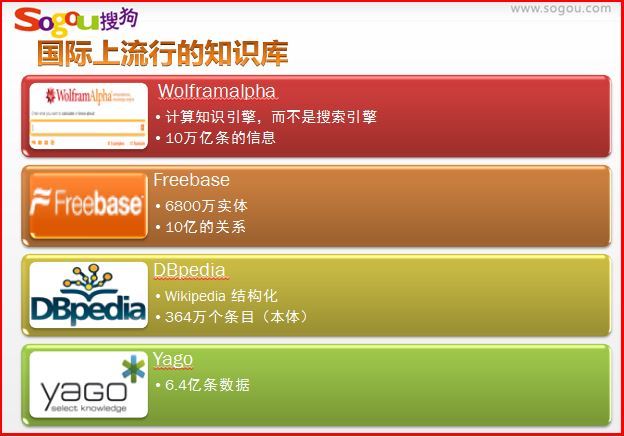
国际上流行的知识库或数据源如下所示:
Wolframalpha: 一个计算知识引擎,而不是搜索引擎。其真正的创新之处,在于能够马上理解问题,并给出答案,在被问到"珠穆朗玛峰有多高"之类的问题时,WolframAlpha不仅能告诉你海拔高度,还能告诉你这座世界第一高峰的地理位置、附近有什么城镇,以及一系列图表。
Freebase: 6800万实体,10亿的关系。Google号称扩展到5亿实体和25亿的关系。所有内容都由用户添加,采用创意共用许可证,可以自由引用。
DBpedia: wikipedia基金会的一个子项目,处于萌芽阶段。DBpedia是一个在线关联数据知识库项目。它从维基百科的词条中抽取结构化数据,以提供更准确和直接的维基百科搜索,并在其他数据集和维基百科之间创建连接,并进一步将这些数据以关联数据的形式发布到互联网上,提供给需要这些关联数据的在线网络应用、社交网站或者其他在线关联数据知识库。
实体构建——实体和属性的抽取
(1) 各类型实体抽取
利用用户搜索记录。该记录保存了用户的标识符、以及用户的查询条目、查询时间、搜索引擎返回的结果以及用户筛选后点击的链接。
该数据集从一定程度上反映了人们对搜索结果的态度,是用户对网络资源的一种人工标识。根据用户搜索记录的数据特点,可用二部图表示该数据,其中qi表示用户的查询条目,uj表示用户点击过的链接,wij表示qi和uj之间的权重,一般是通过用户点击次数进行衡量。
采用随机游走(Random Walk)对用户搜索记录进行聚类,并选出每个类中具有高置信度的链接作为数据来源,同时抽取对应实体,并将置信度较高的实体加入种子实体中,进行下一次迭代。
(2) 属性抽取
a) 半结构化网站,利用Tag path和Text node标识网页,对属性聚类
b) 从查询日志中识别实体+属性名
本体构建中本体编辑推荐使用“Protege JENA”软件。

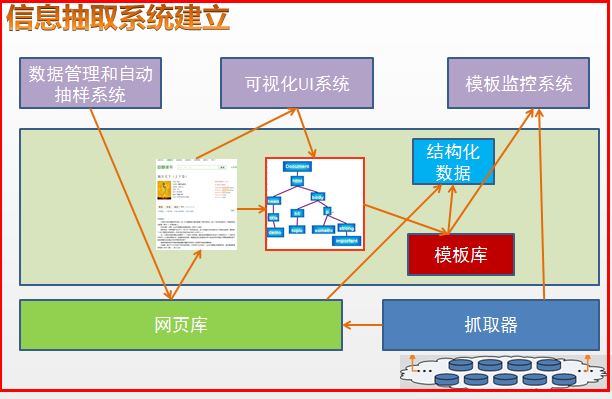
信息抽取系统的建立
如下所示,获取在线百科消息盒的属性和属性值。在这部分,我们选择基于机器学习的排序模型技术。基于多角度全面的海量的用户行为为基础,建立机器学习排序模型。使得搜索结果得到一个更加细致化、全面的效果优化。结构图如下所示:

由于没有任何一个网站有所有的信息,甚至是在一个领域里。为了获取到更加全面的知识,需要整合,这就需要对齐。其中数据源包括:百度百科、豆瓣、起点中文网、互动百科、搜狐娱乐、新浪教育、Freebase等等。
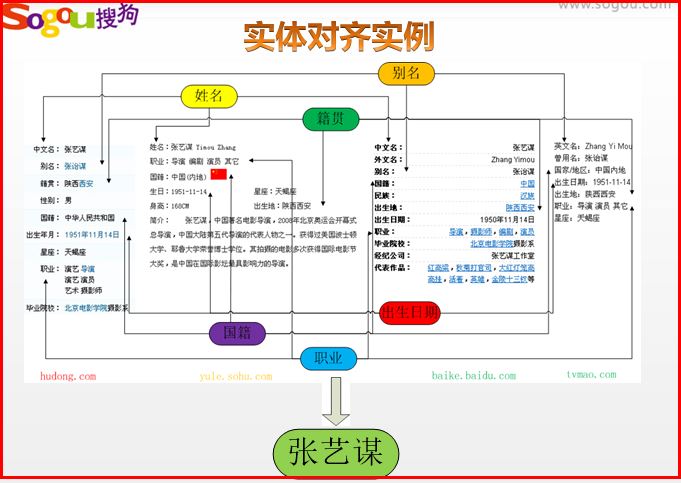
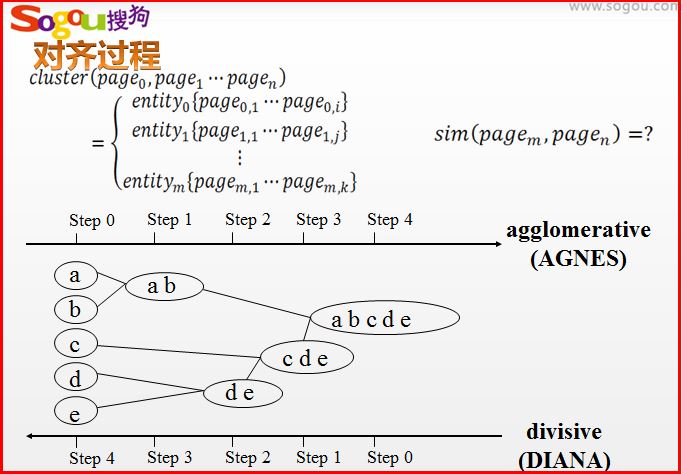
实体对齐
下图是一张经典的实体对齐图。他是对“张艺谋”这个实体进行对齐,数据源来自互动百科、百度百科、tvmao网站、搜狐娱乐。
比如张艺谋的国籍需要对齐“中华人民共和国”、“中国(内地)”、“中国”三个属性值;“国家”、“国籍”、“国籍”需要属性对齐;再如出生日期对齐“1951年11月14日”、“1951-11-14”、“1951-11-14”实现属性值对齐。
另参考我的文章:基于VSM的命名实体识别、歧义消解和指代消解
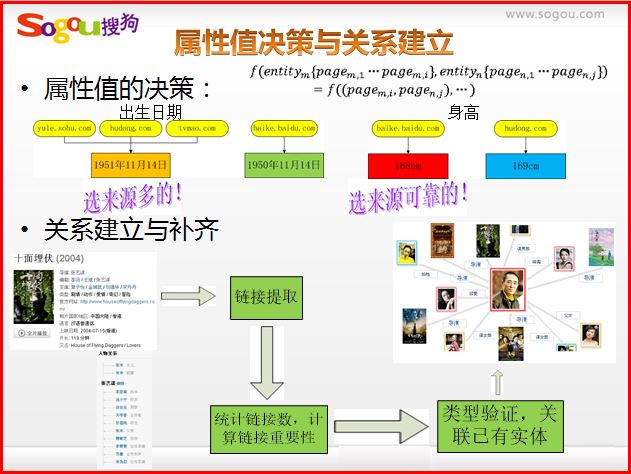
属性值决策与关系建立
属性值决策可以看成是属性值对齐,需要选择来源多的数据,同时来源可靠。
关系建立补齐需要提取链接,再统计链接数,计算链接重要程度,最后关联实体。
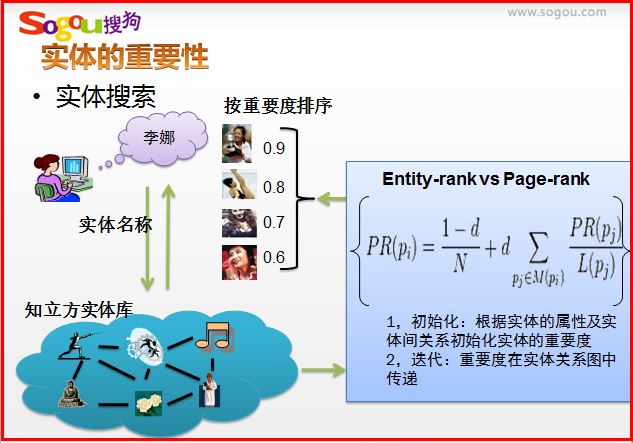
实体搜索
实体搜索如“李娜”,会根据用户的以前搜索记录,真正理解用户搜索,返回结果。辨别它是网球运动员、歌星、舞蹈家或跳水运动员。
推理补充数据与验证
从原始三元组数据,推理生成新的数据,建立更多的实体间的链接关系,增加知识图的边的密度,例如:莫言作品。

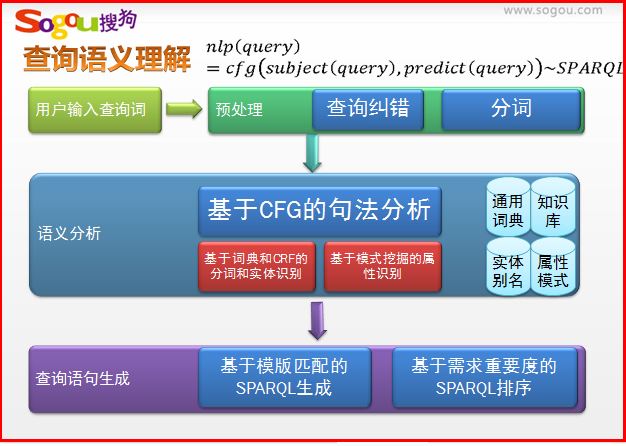
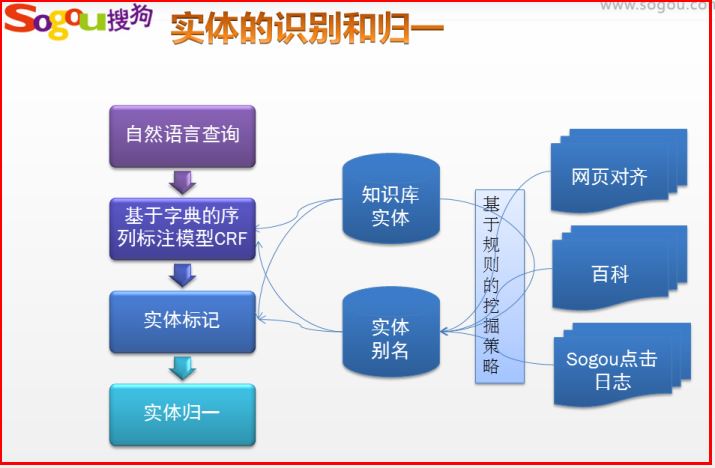
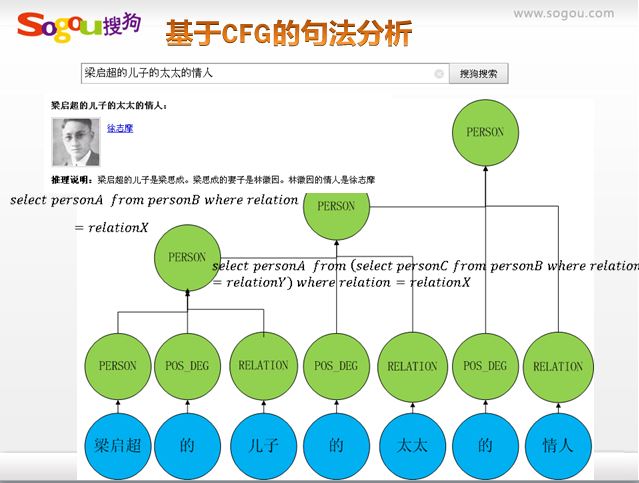
查询语义理解、实体的识别和归一
举例:美国 罗恩尼 女抢匪
美国<Loc> 罗恩尼<Person> 女抢匪<Movie>
美国<Loc> 乔阿吉姆·罗恩尼<Person> 侠盗魅影<Movie>
PS:推荐大家自己去学习CRF相关知识,作者也在学习中
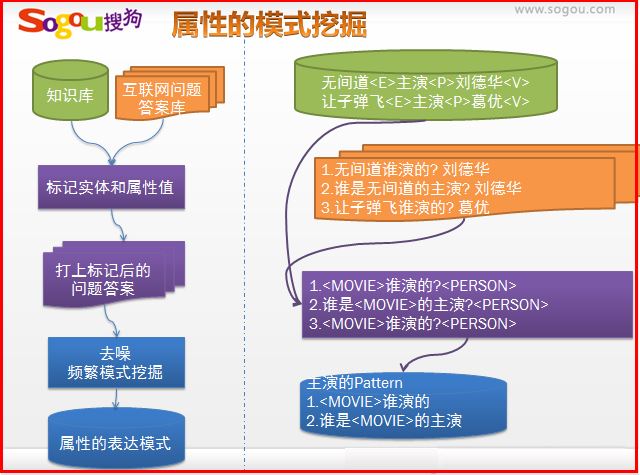
属性的模式挖掘
由于表达方式的多样性,对同一属性,不同人有不同的说法。我们通过挖掘百度知道,来获取属性的各种各样的描述方式。
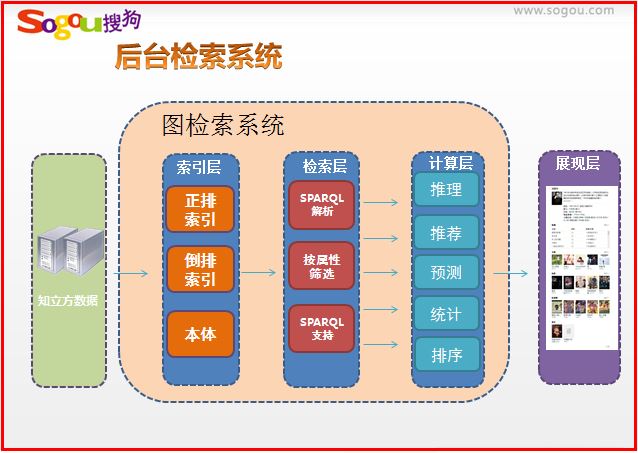
后台检索系统
知立方信息展现:
1.提供知识库信息的展示载体,将知识库的信息转化为用户可以理解的内容;
2.提供更加丰富的富文本信息(不局限于文字,增添图片、动画、表格等);
3.提供更友好的用户交互体验:增加更多的用户交互元素,如图片浏览、点击试听。并能够引导用户在更短的时间获取更多的信息。
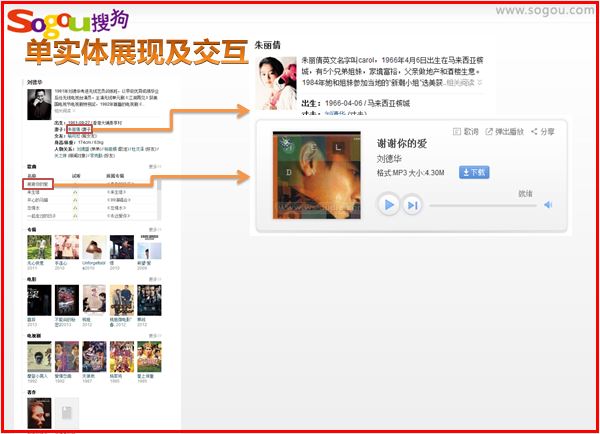
如下图所示:“刘德华”分别点击上方基本信息,点击歌曲,点击属性标签,点击具体的电影。
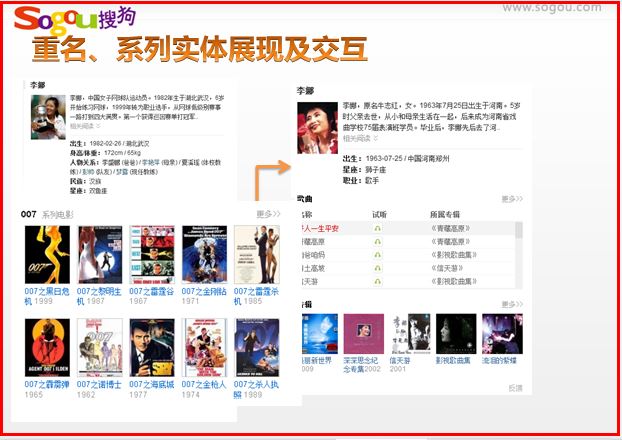
再如重名、系列实体展现如下: “李娜 ”点击其他的同名人物、“十大元帅”点击某个具体的人物、“速度与激情”点击更多,展示更多的系列实体。
关于知识图谱这部分的资料不是很多,而且具体每个步骤是如何实现的资料就更少了。这篇文章主要作为知识图谱的入门介绍,并通过会议叙述了百度知心和搜狗知立方,目前国内研究较早的知识图谱。其中推荐大家看原文PDF,版权也是归他们所有,我只是记录下自己的学习笔记。
总之,希望文章对你有所帮助,由于我没有参加这次会议,所以可能有些错误或不能表述清楚的地方,尤其是具体实现过程,还请海涵,写文不易,且看且珍惜,勿喷~
(By:Eastmount 2015-11-16 深夜2点 http://blog.csdn.net/eastmount/)



