- A+
WechatSogou [1]- 微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。
DouBanSpider [2]- 豆瓣读书爬虫。可以爬下豆瓣读书标签下的所有图书,按评分排名依次存储,存储到Excel中,可方便大家筛选搜罗,比如筛选评价人数>1000的高分书籍;可依据不同的主题存储到Excel不同的Sheet ,采用User Agent伪装为浏览器进行爬取,并加入随机延时来更好的模仿浏览器行为,避免爬虫被封。
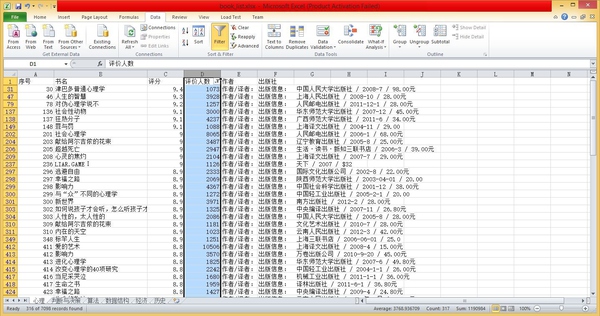
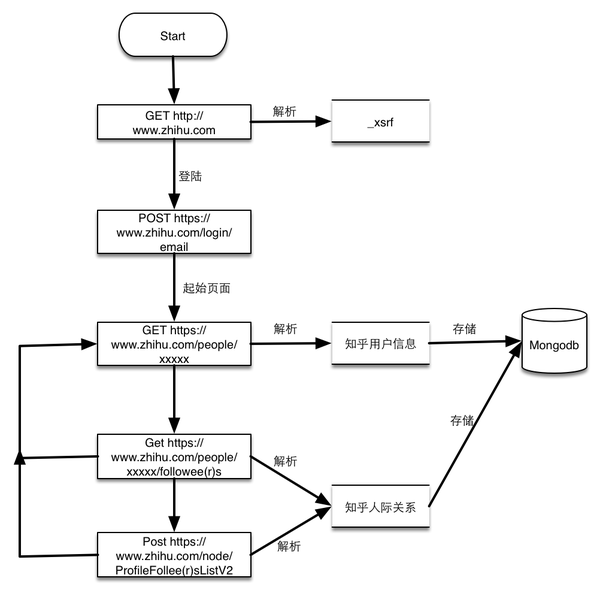
zhihu_spider [3]- 知乎爬虫。此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo
bilibili-user [4]- Bilibili用户爬虫。总数据数:20119918,抓取字段:用户id,昵称,性别,头像,等级,经验值,粉丝数,生日,地址,注册时间,签名,等级与经验值等。抓取之后生成B站用户数据报告。
SinaSpider [5]- 新浪微博爬虫。主要爬取新浪微博用户的个人信息、微博信息、粉丝和关注。代码获取新浪微博Cookie进行登录,可通过多账号登录来防止新浪的反扒。主要使用 scrapy 爬虫框架。
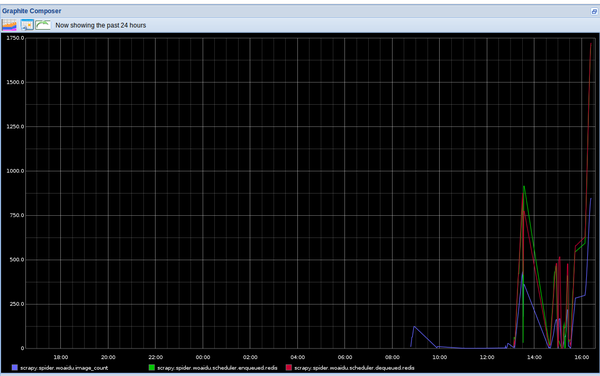
distribute_crawler [6]- 小说下载分布式爬虫。使用scrapy,redis, mongodb,graphite实现的一个分布式网络爬虫,底层存储mongodb集群,分布式使用redis实现,爬虫状态显示使用graphite实现,主要针对一个小说站点。
CnkiSpider [7]- 中国知网爬虫。设置检索条件后,执行src/CnkiSpider.py抓取数据,抓取数据存储在/data目录下,每个数据文件的第一行为字段名称。
LianJiaSpider [8]- 链家网爬虫。爬取北京地区链家历年二手房成交记录。涵盖链家爬虫一文的全部代码,包括链家模拟登录代码。
scrapy_jingdong [9]- 京东爬虫。基于scrapy的京东网站爬虫,保存格式为csv。
QQ-Groups-Spider [10]- QQ 群爬虫。批量抓取 QQ 群信息,包括群名称、群号、群人数、群主、群简介等内容,最终生成 XLS(X) / CSV 结果文件。
 wooyun_public [11]-乌云爬虫。 乌云公开漏洞、知识库爬虫和搜索。全部公开漏洞的列表和每个漏洞的文本内容存在mongodb中,大概约2G内容;如果整站爬全部文本和图片作为离线查询,大概需要10G空间、2小时(10M电信带宽);爬取全部知识库,总共约500M空间。漏洞搜索使用了Flask作为web server,bootstrap作为前端。
wooyun_public [11]-乌云爬虫。 乌云公开漏洞、知识库爬虫和搜索。全部公开漏洞的列表和每个漏洞的文本内容存在mongodb中,大概约2G内容;如果整站爬全部文本和图片作为离线查询,大概需要10G空间、2小时(10M电信带宽);爬取全部知识库,总共约500M空间。漏洞搜索使用了Flask作为web server,bootstrap作为前端。
2016.9.11补充:
QunarSpider [12]- 去哪儿网爬虫。 网络爬虫之Selenium使用代理登陆:爬取去哪儿网站,使用selenium模拟浏览器登陆,获取翻页操作。代理可以存入一个文件,程序读取并使用。支持多进程抓取。
findtrip [13]- 机票爬虫(去哪儿和携程网)。Findtrip是一个基于Scrapy的机票爬虫,目前整合了国内两大机票网站(去哪儿 + 携程)。
163spider [14] - 基于requests、MySQLdb、torndb的网易客户端内容爬虫
doubanspiders [15]- 豆瓣电影、书籍、小组、相册、东西等爬虫集
QQSpider [16]- QQ空间爬虫,包括日志、说说、个人信息等,一天可抓取 400 万条数据。
baidu-music-spider [17]- 百度mp3全站爬虫,使用redis支持断点续传。
tbcrawler [18]- 淘宝和天猫的爬虫,可以根据搜索关键词,物品id来抓去页面的信息,数据存储在mongodb。
stockholm [19]- 一个股票数据(沪深)爬虫和选股策略测试框架。根据选定的日期范围抓取所有沪深两市股票的行情数据。支持使用表达式定义选股策略。支持多线程处理。保存数据到JSON文件、CSV文件。
BaiduyunSpider[20]-百度云盘爬虫。
[1]: GitHub - Chyroc/WechatSogou: 基于搜狗微信搜索的微信公众号爬虫接口 [2]: GitHub - lanbing510/DouBanSpider: 豆瓣读书的爬虫 [3]: GitHub - LiuRoy/zhihu_spider: 知乎爬虫 [4]: GitHub - airingursb/bilibili-user: Bilibili用户爬虫 [5]: GitHub - LiuXingMing/SinaSpider: 新浪微博爬虫(Scrapy、Redis) [6]: GitHub - gnemoug/distribute_crawler: 使用scrapy,redis, mongodb,graphite实现的一个分布式网络爬虫,底层存储mongodb集群,分布式使用redis实现,爬虫状态显示使用graphite实现 [7]: GitHub - yanzhou/CnkiSpider: 中国知网爬虫
[8]: GitHub - lanbing510/LianJiaSpider: 链家爬虫
[9]: GitHub - taizilongxu/scrapy_jingdong: 用scrapy写的京东爬虫
[10]: GitHub - caspartse/QQ-Groups-Spider: QQ Groups Spider(QQ 群爬虫)
[12]: GitHub - lining0806/QunarSpider: 网络爬虫之Selenium使用代理登陆:爬取去哪儿网站
[14]: GitHub - leyle/163spider: 爬取网易客户端内容的小爬虫。
[15]: GitHub - dontcontactme/doubanspiders: 豆瓣电影、书籍、小组、相册、东西等爬虫集 writen in Python
[16]: GitHub - LiuXingMing/QQSpider: QQ空间爬虫(日志、说说、个人信息)
[17]: GitHub - Shu-Ji/baidu-music-spider: 百度mp3全站爬虫
[18]: GitHub - pakoo/tbcrawler: 淘宝天猫 商品 爬虫
[19]: GitHub - benitoro/stockholm: 一个股票数据(沪深)爬虫和选股策略测试框架
[20]:GitHub - k1995/BaiduyunSpider: 爱百应,百度云网盘搜索引擎,爬虫+网站
--------------------------
本项目收录各种Python网络爬虫实战开源代码,并长期更新,欢迎补充。
更多Python干货欢迎关注:
微信公众号:Python中文社区Python初级技术交流QQ群:152745094Python高级技术交流QQ群:273186166Python网络爬虫组QQ群:206241755PythonWeb开发组QQ群:577672548Python量化交易策略组QQ群:264204289Python数据分析挖掘组QQ群:539956362Python自然语言处理组QQ群:570364809
--------------------------
Python学习资源下载:
Python学习思维脑图大全汇总打包 (密码请关注微信公众号“Python中文社区”后回复“思维”二字获取)



