- A+
掌握多少知识,就能抓住多少机会。“知识”来源于“信息”的提炼,而“信息”来源于“数据”的分析。从“数据”→“信息”→“知识”→“智慧”是一步步转化而来。
想从互联网领域中学习什么东西,不同于学校,老师可以直接给予学生现成的知识。互联网高速发展、不易预测的特性,导致大部分信息仍处于未知的状态,没有多少人会告诉你有什么信息、有什么知识。很多信息还躺在一坨坨数据中等待被分析出来。
所以我觉得,在互联网行业中,数据获取与分析是如同沟通表达、时间管理一样的通用型技能,是可以不受职能控制而进行转移。
数据可以通过交换、购买、API等方式来获得,但如果其他人都没有,那就只能自己去找数据,然后分析出信息,提炼出知识。
举个例子,曾经为了分析排在百度首页的网页都有什么共同特征,自己指定了几个可能影响排名的因素:网页大小、下载速度、网页链接数量、正文字数、url的目录层级、query在正文的出现次数、query分词后的词项在正文中的出现次数、query在title中的出现次数等十几个指标,拿了5000个长尾词跑百度搜索结果,把前5页出现的网页全部抓下来,跑出前面指定的十几个指标对应的数据,然后分析所处不同分页的网页(每个分页个5万个样本),在指标上有什么明显的规律。
以上是获取数据,对数据分析后发现:
1、排在第一页的结果,平均正文字数500,第二页~第五页的结果依次递减;
2、排在第一页的结果,平均网页包含的链接数量130,第二页~第五页的结果依次递增;
3、其他指标,在所有分页中均无明显波动。
以上是信息,对信息进行提炼,形成知识:
1、网页正文字数和网页包含的链接会影响长尾词的排名
2、覆盖长尾词的页面,保证正文字数控制在500字以上,网页中包含的链接控制在130以下,会提高网页出现在百度首页的概率
当然,真实的网页排序因素远比这个复杂多得多,除了以上两点肯定还要同时满足多个条件才能出现在首页。
另外,还需注意获取的数据的可靠性和公正性,可靠性是数据能不能推导出正确的结论;公正性是这个数据是不是公平的。
还是上面的例子,如果换成5000个热词,那计算出来的结果就不可靠也不公正。因为百度是一个商业搜索引擎,而在长尾词上,百度会相对不那么商业。
做流量的,很多数据得需要自己去抓,抓取就要用到爬虫。花了几天时间体验了下python的Scrapy,感觉不错,是一个高性能、易上手、健壮稳定、可高度定制、可分布的爬虫框架。
作为一个成熟的爬虫框架,肯定比自己现手写一个爬虫要来的快的多,而相比火车头,它能实现火车头实现不了的功能,比如上面说的例子。
下面是Scrapy的使用小记(抓取百度搜索结果,此处宜横屏浏览,也可以点击左下角“阅读原文”到博客中浏览...)
项目构成:

scrapy.cfg:项目配置文件
items.py:存放抓取数据的
pipelines.py:处理抓取数据的
settings.py:爬虫配置文件,有现成的API,可添加各种防ban策略
middlewares.py:中间件
dmoz_spider.py:爬虫程序
参照官方文档和Google写了个抓取百度排名的程序,上手后,在配置速度比火车头还要快一些。
考虑百度封闭爬虫比较严,需要一些防屏蔽策略,采用如下方法实现:
1、轮换出口IP
用scrapinghub提供的代理,因为是国外的IP,所以访问百度比国内要慢一些,但是提供的代理很稳定,方便配置,且免费,貌似没有使用次数的限制。
在sittings.py中添加:
'''crawlera账号、密码'''
CRAWLERA_ENABLED = True
CRAWLERA_USER = '账号'
CRAWLERA_PASS = '密码'
'''下载中间件设置'''
DOWNLOADER_MIDDLEWARES = {
'scrapy_crawlera.CrawleraMiddleware': 600
}
2、轮换UA
在sittings.py添加:
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
.......
]
'''下载中间件设置'''
DOWNLOADER_MIDDLEWARES = {
'tutorial.middlewares.RandomUserAgent': 1,
}
在middlewares.py添加:
class RandomUserAgent(object):
"""Randomly rotate user agents based on a list of predefined ones"""
def __init__(self, agents):
self.agents = agents
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings.getlist('USER_AGENTS'))
def process_request(self, request, spider):
#print "**************************" + random.choice(self.agents)
request.headers.setdefault('User-Agent', random.choice(self.agents))
3、轮换Cookie,并完全模拟浏览器请求头
在sittings.py添加:
def getCookie():
cookie_list = [
'cookie1', #自己从不同浏览器中获取cookie在添加到这
'cookie2',
......
]
cookie = random.choice(cookie_list)
return cookie
'''设置默认request headers'''
DEFAULT_REQUEST_HEADERS = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Host':'www.baidu.com',
'RA-Sid':'7739A016-20140918-030243-3adabf-48f828',
'RA-Ver':'3.0.7',
'Upgrade-Insecure-Requests':'1',
'Cookie':'%s' % getCookie()
}
sittings.py添加其他配置项:
'''下载延时,即下载两个页面的等待时间'''
DOWNLOAD_DELAY = 0.5
'''并发最大值'''
CONCURRENT_REQUESTS = 100
'''对单个网站并发最大值'''
CONCURRENT_REQUESTS_PER_DOMAIN = 100
'''启用AutoThrottle扩展,默认为False'''
AUTOTHROTTLE_ENABLED = False
'''设置下载超时'''
DOWNLOAD_TIMEOUT = 10
'''降低log级别,取消注释则输出抓取详情'''
LOG_LEVEL = 'INFO'
蜘蛛程序:dmoz_spider.py
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["www.baidu.com"]
# start_urls = ['http://www.baidu.com/s?q=&tn=baidulocal&ct=2097152&si=&ie=utf-8&cl=3&wd=SEO%E5%9F%B9%E8%AE%AD']
start_urls = []
for word in open('/Users/sunjian/Desktop/tutorial/tutorial/spiders/word.txt'):
word = word.strip()
url = 'http://www.baidu.com/s?q=&tn=baidulocal&ct=2097152&si=&ie=utf-8&cl=3&wd=%s' % urllib.quote(word)
start_urls.append(url)
def __get_url_query(self, url):
m = re.search("wd=(.*)", url).group(1)
return m
def parse(self,response):
n = 0
for sel in response.xpath('//td[@class="f"]'):
query = urllib.unquote(self.__get_url_query(response.url))
item = DmozItem()
title = re.sub('<[^>]*?>','',sel.xpath('.//a/font[@size="3"]').extract()[0])
lading = sel.xpath('.//a[1]/@href').extract()[0]
time = sel.xpath('.//font[@color="#008000"]/text()').re('(d{4}-d{1,2}-d{1,2})')[0]
size = sel.xpath('.//font[@color="#008000"]/text()').re('(d+K)')[0]
n += 1
item['rank'] = n
item['title'] = title.encode('utf8')
item['lading'] = lading.encode('utf8')
item['time'] = time.encode('utf8')
item['size'] = size.encode('utf8')
item['query'] = query
yield item
抓取数据写入mysql
在piplines.py添加:
class MySQLTutorialPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbargs = dict(
host=settings['MYSQL_HOST'],
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWD'],
charset='utf8',
cursorclass = MySQLdb.cursors.DictCursor,
use_unicode= True,
)
dbpool = adbapi.ConnectionPool('MySQLdb', **dbargs)
return cls(dbpool)
#pipeline默认调用
def process_item(self, item, spider):
d = self.dbpool.runInteraction(self._do_upinsert, item, spider)
d.addErrback(self._handle_error, item, spider)
d.addBoth(lambda _: item)
return d
#将每行更新或写入数据库中
def _do_upinsert(self, conn, item, spider):
conn.execute(""" INSERT INTO baidu_pc_rank VALUES ('%s','%s','%s','%s','%s','%s') """ % (item['rank'],item['title'],item['lading'],item['time'],item['size'],item['query']))
#获取url的md5编码
def _get_linkmd5id(self, item):
#url进行md5处理,为避免重复采集设计
return md5(item['address']).hexdigest()
#异常处理
def _handle_error(self, failue, item, spider):
log.err(failure)
在settings.py添加:
MYSQL_HOST = '127.0.0.1'
MYSQL_DBNAME = 'se_rank'
MYSQL_USER = 'root'
MYSQL_PASSWD = ''
ITEM_PIPELINES = {
'tutorial.pipelines.MySQLTutorialPipeline': 400,
}
运行爬虫:
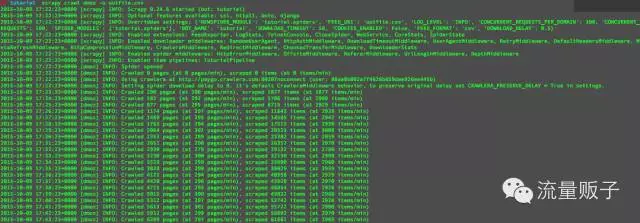
每分钟抓300左右个页面,在速度上仍有很大提升空间,起码要用国内代理速度会快很多。以上防ban功能适用于所有网站,再抓另一个网站只要做对应修改便可。
抓取数据写入mysql情况:
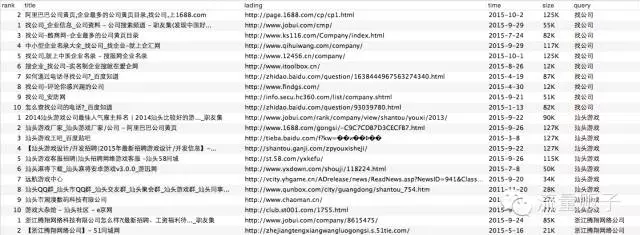
完整代码已更新到博客,点击左下角“阅读原文”进入。
欢迎关注扫描下图二维码,关注“流量贩子”,可查看历史消息阅读更多优质文章。
微信公众号:流量贩子

扫描上图“识别图中二维码”以快速关注
文章来源:流量贩子公众帐号,扫描上面的二维码关注,干货多多!


来自外部的引用: 3