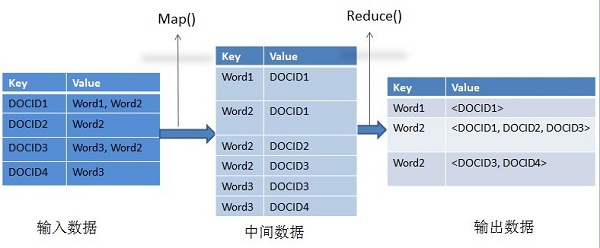
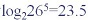- A+
Hilltop算法是由Krishna Baharat 在2000年左右研究的,于2001年申请专利,但是有很多人以为Hilltop算法是由谷歌研究的。只不过是Krishna Baharat 后来加入了Google成为了一名核心工程师,然后授权给Google使用的。
在与PageRank算法相比之下,Google意识到这个算法的进步会为他们的搜索排名带来非常重要的功能。Google的HillTop算法现在已经能更好的与旧的算法(PR算法)联合起来工作。根据观察HillTop算法比起它在2000年刚设计的时候已经有了很大的进步。显然这也是2003年11月16日“佛罗里达”更新中影响的一个最主要的算法。
1. Hilltop算法基本思想
Hilltop融合了HITS和PageRank两个算法的基本思想:
一方面,Hilltop是与用户查询请求相关的链接分析算法,吸收了HITS算法根据用户查询获得高质量相关网页子集的思想,即主题相关网页之间的链接对于权重计算的贡献比主题不相关的链接价值要更高.符合“子集传播模型”,是该模型的一个具体实例;
另一方面,在权值传播过程中,Hilltop也采纳了PageRank的基本指导思想,即通过页面入链的数量和质量来确定搜索结果的排序权重。
2. Hilltop算法的一些基本定义
非从属组织页面:
“非从属组织页面”(Non-affiliated Pages)是Hilltop算法的一个很重要的定义。要了解什么是非从属组织页面,先要搞明白什么是“从属组织网站”,所谓“从属组织网站”,即不同的网站属于同一机构或者其拥有者有密切关联。具体而言,满足如下任意一条判断规则的网站会被认为是从属网站:
条件1:主机IP地址的前三个子网段相同,比如:IP地址分别为159.226.138.127和159.226.138.234的两个网站会被认为是从属网站。
条件2:如果网站域名中的主域名相同,比如:www.ibm.com和www.ibm.com.cn会被认为是从属组织网站。
“非从属组织页面”的含义是:如果两个页面不属于从属网站,则为非从属组织页面。图6-22是相关示意图,从图中可以看出,页面2和页面3同属于IBM的网页,所以是“从属组织页面”,而页面1和页面5、页面3和页面6都是“非从属组织页面”。由此也可看出,“非从属组织页面”代表的是页面的一种关系,单个一个页面是无所谓从属或者非从属组织页面的。
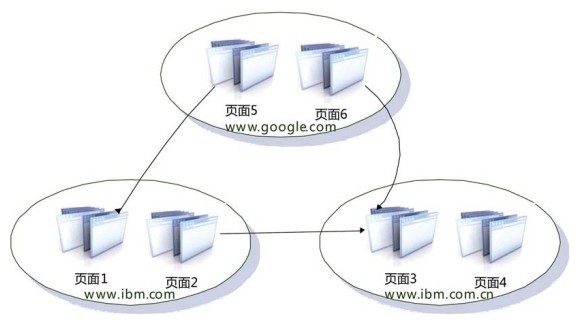
图6-22 “从属组织页面”与“非从属组织页面”
专家页面:
“专家页面”(Export Sources)是Hilltop算法的另外一个重要定义。所谓“专家页面”,即与某个主题相关的高质量页面,同时需要满足以下要求:这些页面的链接所指向的页面相互之间都是“非从属组织页面”,且这些被指向的页面大多数是与“专家页面”主题相近的。
目标页面集合:
Hilltop算法将互联网页面划分为两类子集合,最重要的子集合是由专家页面构成的互联网页面子集,不在这个子集里的剩下的互联网页面作为另外一个集合,这个集合称作“目标页面集合”(Target Web Servers)。
3. Hilltop算法
图6-23是Hilltop算法的整体流程示意。
1) 建立专家页面索引:首先从海量的互联网网页中通过一定规则筛选出“专家页面”子集合,并单独为这个页面集合建立索引。
2)用户查询: Hilltop在接收到用户发出的某个查询请求时:
首先) 根据用户查询的主题,从“专家页面”子集合中找出部分相关性最强的“专家页面”,并对每个专家页面计算相关性得分,
然后)根据“目标页面”和这些“专家页面”的链接关系来对目标页面进行排序。基本思路遵循PageRank算法的链接数量假设和质量原则,将专家页面的得分通过链接关系传递给目标页面,并以此分数作为目标页面与用户查询相关性的排序得分。
最后) 系统整合相关专家页面和得分较高的目标页面作为搜索结果返回给用户。
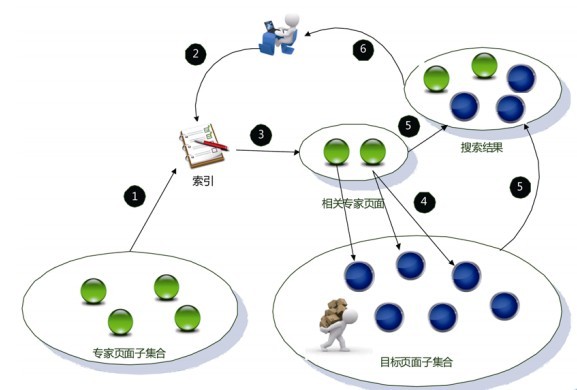
图6-23 Hilltop算法流程
若在上述过程中,Hilltop无法得到一个足够大的专家页面集合,则返回搜索结果为空。由此可以看出,Hilltop算法更注重搜索结果的精度和准确性,不太考虑搜索结果是否足够多或者对大多数用户查询是否都有相应的搜索结果,所以很多用户发出的查询的搜索结果为空。这意味着Hilltop可以与某个排序算法相结合,以提高排序准确性,但并不适合作为一个独立的网页排序算法来使用。
4. Hilltop算法流程
从上述整体流程描述可看出,Hilltop算法主要包含两个步骤:专家页面搜索及目标页面排序。
步骤一:专家页面搜索
Hilltop算法从1亿4千万网页中,通过计算筛选出250万规模的互联网页面作为“专家页面”集合。“专家页面”的选择标准相对宽松,同时满足以下两个条件的页面即可进入“专家页面”集合:
条件1:页面至少包含k个出链,这里的数量k可人为指定;
条件2:k个出链指向的所有页面相互之间的关系都符合“非从属组织页面”的要求;
当然,在此基础上,可以设定更严格的筛选条件,比如要求这些“专家页面”所包含链接指向的页面中,大部分所涉及的主题和专家页面的主题必须是一致或近似的。
根据以上条件筛选出“专家页面”后,即可对“专家页面”单独建索引,在此过程中,索引系统只对页面中的“关键片段”(Key Phrase)进行索引。所谓“关键片段”,在Hilltop算法里包含了网页的三类信息:网页标题、H1标签内文字和URL锚文字。
网页的“关键片段”可以支配(Qualify)某个区域内包含的所有链接,“支配”关系代表了一种管辖范围,不同的“关键片段”支配链接的区域范围不同,具体而言:
页面标题可以支配页面内所有出现的链接,
H1标签可以支配包围在<H1>和</H1>内的所有链接,
URL锚文字只能支配本身唯一的链接。
图6-24给出了“关键片段”对链接支配关系的示意图,在以“奥巴马访问中国”为标题的网页页面中,标题支配了所有这个页面出现的链接,而H1标签的管辖范围仅限于标签范围内出现的2个链接,对于锚文字“中国领导人”来说,其唯一能够支配的就是本身的这个链接。之所以定义这种支配关系,对于第二阶段将“专家页面”的分值传递到“目标页面”时候会起作用。
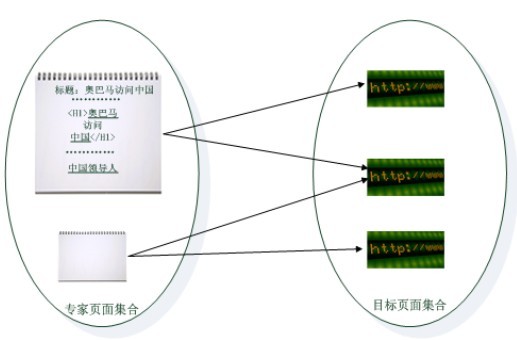
图6-24 “关键片段”链接支配关系
系统接收到用户查询Q,假设用户查询包含了多个单词,Hilltop如何对“专家页面”进行打分呢?对“专家页面”进行打分主要参考以下三类信息:
1)“关键片段”包含了多少查询词,包含查询词越多,则分值越高,如果不包含任何查询词,则该“关键片段”不计分;
2)“关键片段”本身的类型信息,网页标题权值最高,H1标签次之,再次是链接锚文字;
3)用户查询和“关键片段”的失配率,即“关键片段”中不属于查询词的单词个数占“关键片段”总单词个数,这个值越小越好,越大则得分衰减越多;
Hilltop综合考虑以上三类因素,拟合出打分函数来对“专家页面”是否与用户查询相关进行打分,选出相关性分值足够高的“专家页面”,以进行下一步骤操作,即对“目标页面”进行相关性计算。
步骤二:目标页面排序
Hilltop算法包含一个基本假设,即认为一个“目标页面”如果是满足用户查询的高质量搜索结果,其充分必要条件是该“目标页面”有高质量“专家页面”链接指向。然而,这个假设并不总是成立,比如有的“专家页面”的链接所指向的“目标页面”可能与用户查询并非密切相关。所以,Hilltop算法在这个阶段需要对“专家页面”的出链仔细进行甄别,以保证选出那些和查询密切相关的目标页面。
Hilltop在本阶段是基于“专家页面”和“目标页面”之间的链接关系来进行的,在此基础上,将“专家页面”的得分传递给有链接关系的“目标页面”。传递分值之前,首先需要对链接关系进行整理,能够获得“专家页面”分值的“目标页面”需要满足以下两点要求:
条件1:至少需要两个“专家页面”有链接指向“目标页面”,而且这两个专家页面不能是“从属组织页面”,即不能来自同一网站或相关网站。如果是“从属组织页面”,则只能保留一个链接,抛弃权值低的那个链接;
条件2:“专家页面”和所指向的“目标页面”也需要符合一定要求,即这两个页面也不能是“从属组织页面”;
在步骤一,给定用户查询,Hilltop算法已经获得相关的“专家页面”及其与查询的相关度得分,在此基础上,如何对“目标页面”的相关性打分?上面列出的条件1指出,能够获得传递分值的“目标页面”一定有多个“专家页面”链接指向,所以“目标页面”所获得的总传播分值是每个有链接指向的“专家页面”所传递分值之和。而计算其中某个“专家页面”传递给“目标页面”权值的时候是这么计算的:
a. 找到“专家页面” 中那些能够支配目标页面的“关键片段”集合S;
b. 统计S中包含用户查询词的“关键片段”个数T,T越大传递的权值越大;
c.“专家页面”传递给“目标页面”的分值为:E*T,E为专家页面本身在第一阶段计算得到的相关得分,T为b步骤计算的分值,
我们以图6-25的具体例子来说明。假设“专家页面”集合内存在一个网页P,其标题为:“奥巴马访问中国”,网页内容由一段<H1>标签文字和另外一个单独的链接锚文字组成。该页面包含三个出链,其中两个指向“目标页面集合”中的网页www.china.org,另外一个指向网页www.obama.org。出链对应的锚文字分别为:“奥巴马”,“中国”和“中国领导人”。
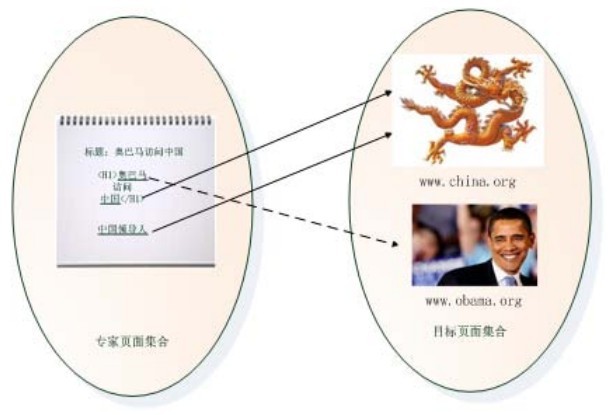
图6-25 Hilltop算法分值传递
从图示的链接关系可以看出,网页P中能够支配www.china.org这个目标页面的“关键片段”集合包括:{中国领导人,中国,<H1>奥巴马访问中国</H1>,标题:奥巴马访问中国}。而能够支配www.obamba.org目标页面的“关键片段”集合包括:{奥巴马,<H1>奥巴马访问中国</H1>,标题:奥巴马访问中国}。
接下来我们分析“专家页面”P在接收到查询时,是怎样将分值传递给与其有链接关系的“目标页面”的。假设系统接收到的查询请求为“奥巴马”,在接收到查询后,系统首先根据上述章节所述,找出“专家页面”并给予分值,而网页P是作为“专家页面”其中一个页面,并获得了相应的分值S,我们重点关注分值传播步骤。
对于查询“奥巴马”来说,网页P中包含这个查询词的“关键片段”集合为:{奥巴马,<H1>奥巴马访问中国</H1>,标题:奥巴马访问中国},如上所述,这三个“关键片段”都能够支配www.obama.org页面,所以网页P传递给www.obamba.org的分值为S*3。而对于目标页面www.china.org来说,这三个“关键片段”中只有{<H1>奥巴马访问中国</H1>,标题:奥巴马访问中国}这两个能够支配目标页面,所以网页P传递给www.china.org的分值为S*2。
对于包含多个查询词的用户请求,则每个查询词单独如上计算,将多个查询词的传递分值累加即可。
5. Hilltop在应用中不足
专家页面的搜索和确定对算法起关键作用,专家页面的质量决定了算法的准确性;而专家页面的质量和公平性在一定程度上难以保证。 Hiltop忽略了大多数非专家页面的影响。
在Hilltop的原型系统中,专家页面只占到整个页面的1.79%,不能全面反映民意。
Hilltop算法在无法得到足够的专家页面子集时(少于两个专家页面),返回为空,即Hilltop适合于对查询排序进行求精,而不能覆盖。这意味着Hilltop可以与某个页面排序算法结合,提高精度,而不适合作为一个独立的页面排序算法。
Hilltop存在与HITS算法类似的计算效率问题,因为根据查询主题从“专家页面”集合中选取主题相关的页面子集也是在线运行的,这与前面提到的HITS算法一样会影响查询响应时间。随着“专家页面”集合的增大,算法的可扩展性存在不足之处。
参考文献:《这就是搜索引擎:核心技术详解》第六章
原文链接:http://blog.csdn.net/hguisu/article/details/8021036