- A+
0x00 前言
做GA业务从目标处拿回原始数据后,通常还需要根据客户的需求对数据进行查询、分析、统计等操作。而大一点的目标拿回的流水数据动辄上亿条,普通数据库即使建了索引也难以支撑如此庞大数据量的查询操作,使用体验极差。
最近发现elk号称可以支持千亿级数据查询,试用后发现查询效率真的不错,虽然我没有千亿的数据,但实测支持几十亿数据查询绰绰有余。这周就写文章给大家介绍一下如何搭建和使用elk。
0x01 食用指南
这是一个分享安全技术的公众号啦,很多东西都会有所涉及但不会深入。本文仅适合那些想快速上手使用elk处理大量静态的数据,而不在乎原理和更多高级玩法的人观看。
对于想钻研大数据领域,深入学习elk的读者,推荐找一些完善的课程、书籍或啃官方文档去系统性学习,本文讲elk相对那些专业的教程是比较业余的。
0x02 elk背景知识
1、什么是ELK
先简要介绍一下elk,如lamp集成环境一样,elk不是一个产品,而是elastic公司的三个产品的合称:
(1)Elasticsearch:开源分布式搜索和分析引擎,提供搜集、分析、存储数据三大功能。
(2)Logstash:具有实时传输能力的数据收集引擎,日志的搜集与分析,过滤日志工具。
(3)Kibana:提供日志分析友好的web界面,可以在es的索引中查找交互数据,生成各种图表。
简单地说,elasticsearch用于存储数据,logstash用于导入数据,kibana用于查询数据。
现在ELK中还新增了一个FileBeat工具,看了介绍大概相当于一个性能更高但少了过滤功能的logstash,不符合本文需求所以下面不会提及这个工具。
2、为什么需要ELK
elk主要的使用场景是处理日志。
集中化日志管理:分布式多节点日志归档、文本搜索、多维度查询
功能需求:收集、传输、存储、分析、警告
3、基本原理
es底层使用Lucene编写,核心功能为全文检索,通过倒排索引来实现。
一些基本概念:
Index(索引):一类业务数据的集合,类似于传统数据库的DB概念,和传统数据库的索引意义完全不同。
Document(文档):数据存储和检索的基本单位。一条完整的数据记录,json格式,类似于传统数据库的一行。
Field(字段):文档的具体一个属性,类似于传统数据库的列。
Term(分词):全文检索特有词汇,存储文档或检索时会先把传入的值进行拆分,使用拆分后的词进行存储和检索。
es将要取消的type概念:
本意是为了类比传统数据库,降低学习成本:index类比为database、type类比为table。但是后面发现两种数据库存储数据的方式和原理完全不同,这种类比毫无意义且降低数据库的效率。所以在es7版本一个index只能有一个type:_doc。es8版本将完全取消type的概念,官方也不建议继续使用type。
0x03 安装搭建elk
配置参考:win10的ubuntu子系统,8G内存,i7-6700 CPU @ 3.40GHz,导入数据使用SSD,存储及查询数据使用机械硬盘 (一台老古董,后面实测es的性能基于这个配置)
主讲linux系统如何搭建,不过也会提一句windows。
1、新建用户
elk不允许root用户启动,新建一个用户elk,用于后续操作。

windows系统不用管。
2、下载elk
下载Elasticsearch、Logstash、Kibana,安装包版本要一致
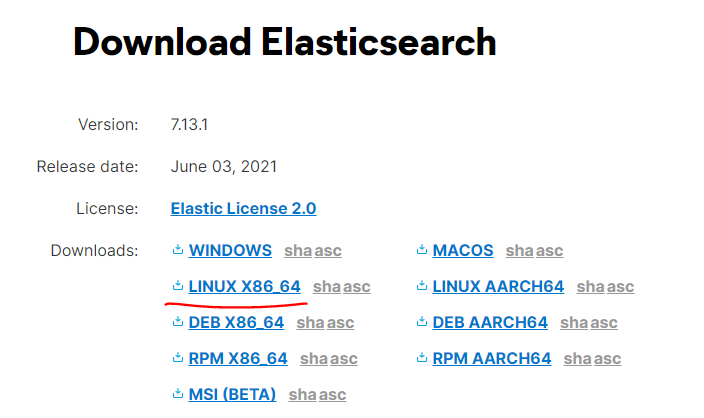
下载地址:https://www.elastic.co/cn/downloads/
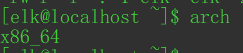
linux系统用arch命令查看架构,然后下载对应安装包。

windows系统使用迅雷下载更快速。
下载后linux用tar -xzvf命令解压,windows用压缩工具解压
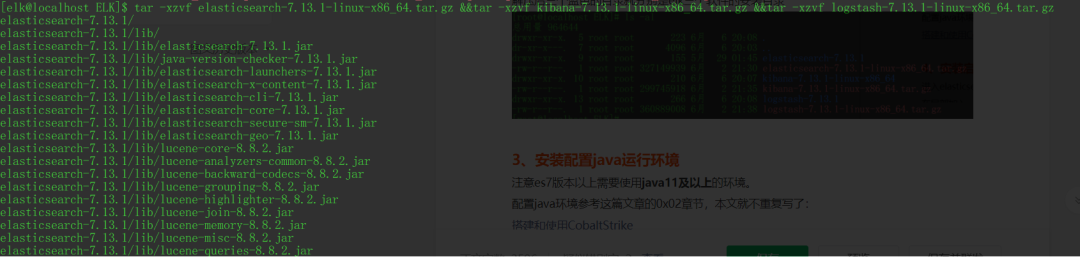
解压后三个蓝色的目录就分别是elk三个软件的安装目录
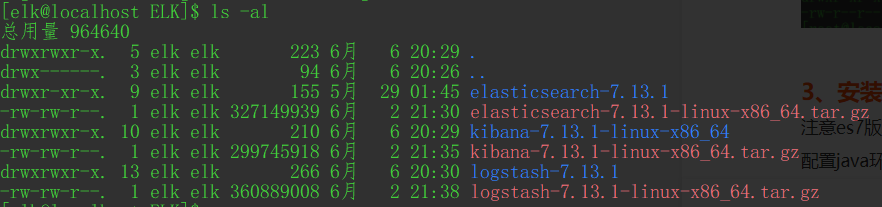
3、安装配置java运行环境
注意es7版本以上需要使用java11及以上的环境。
配置java环境参考这篇文章的0x02章节,本文就不重复写了:
4、安装启动elasticsearch
进入elasticsearch安装目录下的config目录,编辑elasticsearch.yml文件
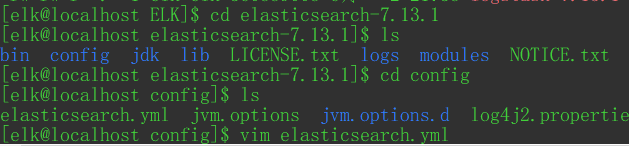
在尾部加入
cluster.name: elknode.name: elasticsearchnetwork.host: 127.0.0.1http.port: 9200http.cors.enabled: truehttp.cors.allow-origin: "*"path.data: home/elk/datapath.logs: /home/elk/logs
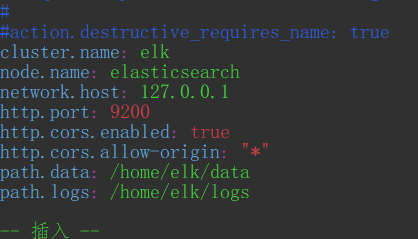
其中path.data和path.logs是数据和运行日志的存储目录,这个根据自身情况自定义,注意权限问题(elk用户需要有目录的读写权限)。
linux如何启动elasticsearch:
./es安装目录/bin/elasticsearch 或
./es安装目录/bin/elasticsearch &(在后台启动)
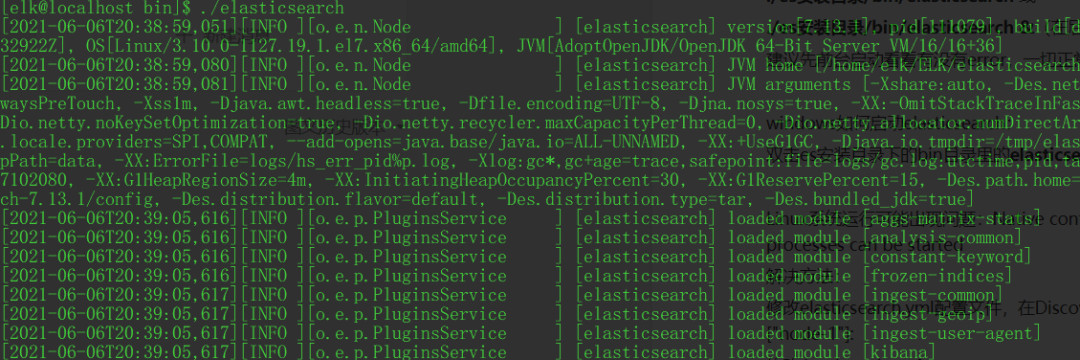
建议先前台启动看看有没有error,一切正常的话ctrl+c掉再后台启动。
Linux系统运行可能出现问题:
Native controller process has stopped - no new native processes can be started
解决方法:
修改elasticsearch.yml配置文件,在Discovery栏下加上
cluster.initial_master_nodes: ["node-1"]
然后修改/etc/sysctl.conf
添加配置vm.max_map_count=655360
然后sudo sysctl --system
windows如何启动elasticsearch:
双击es安装目录下的bin目录里的elasticsearch.bat
测试:
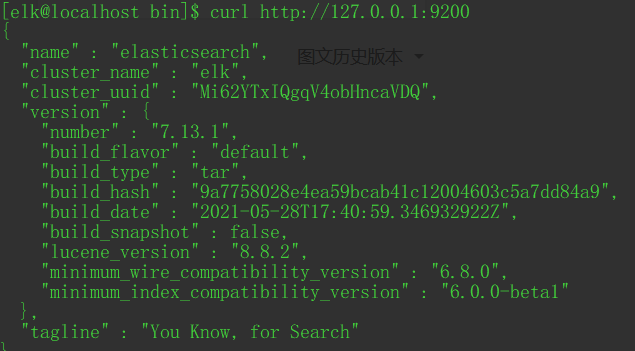
使用curl或用浏览器访问 http://127.0.0.1:9200/,可以看到es的信息
5、安装启动Kibana
进入kibana安装目录的config目录
编辑kibana.yml文件,在末尾加入
server.port: 5601server.host: "127.0.0.1"elasticsearch.hosts: ["http://localhost:9200/"]kibana.index: ".kibana"i18n.locale: "zh-CN"
如果想远程访问,可以把server.host的值改成"0.0.0.0",注意安全问题

linux普通启动:
./kibana安装目录/bin/kibana
linux后台启动:
nohup ./kibana安装目录/bin/kibana &
windows普通启动:
双击kibana安装目录的bin目录下的kabana.bat
windows后台运行:
在kibana.bat同目录下新建文件kibana.vbs,内容如下,双击运行
createobject("wscript.shell").run "kibana.bat",0
想结束进程去任务管理器找Node.js: Server-side JavaScript
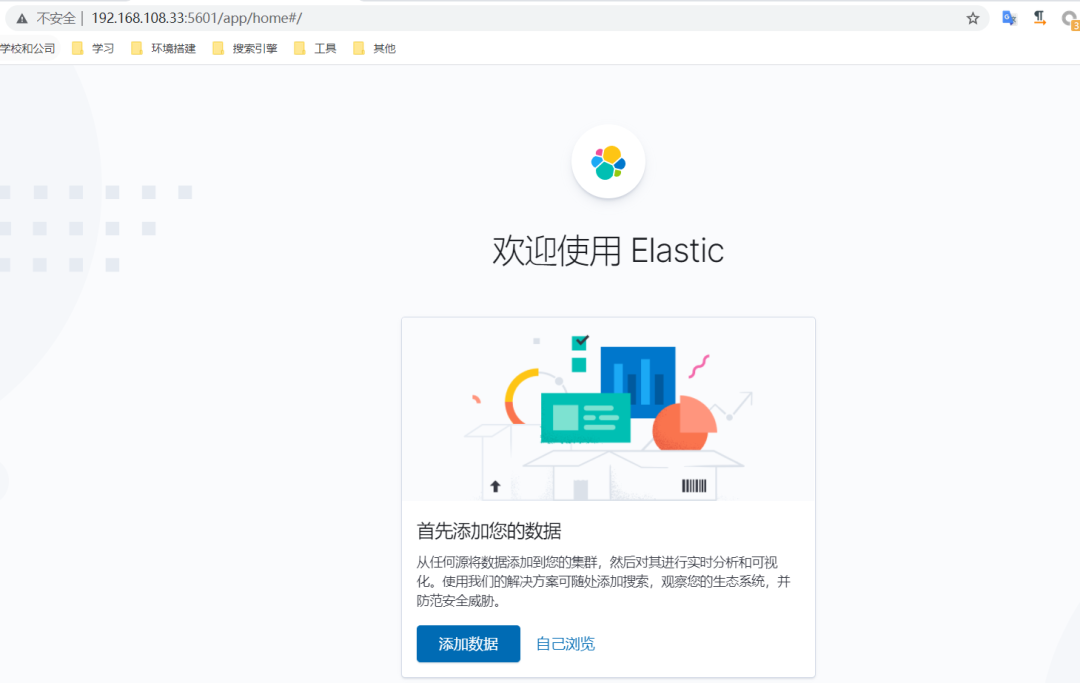
测试:
浏览器访问:http://127.0.0.1:5601/app/home
如果远程访问响应超时,注意检查系统防火墙和云服务器的安全组配置。

6、安装启动logstash
logstash需要根据数据文件的格式编写配置文件,并在其中指定需要导入的数据库文件路径,然后执行。
配置文件的编写方法和logstash的使用方法放在下一章节。
0x04 使用elk处理数据
1、数据结构设计与清洗
数据结构设计:
将一行数据划分成几个字段,可以增加查询的效率。
但是,如果效率没到瓶颈的话,完全不用设计,可以把所有数据写到同一个field里,这样导入不同来源、不同格式的数据时就不用更改logstash的配置文件,简单快捷。
而且elasticsearch全文检索的特性也使它可以在一个field里也能正确的匹配不同格式数据的关键词从而查询到正确的结果。
比如我有这样一个数据:
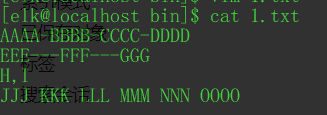
四行数据每行的列数都不同,使用的分隔符也不同,将它们导入到同一个filed中。可以看到es能完美的划分关键词并查询出每行数据。

编码问题:
因为我们要处理的是行数上亿的超大文件,所以尽量避免对源文件做改动(会很慢),所以无需更改源文件编码,只需在logstash导入时指定一下源文件使用的编码即可,logstash输出时会自动转换成utf-8编码,查询时不会出现乱码情况。
如何查看超大文件的编码呢,在windows下可以用emeditor专业版打开文件,linux可以将文件切一小片出来,然后vim进去输入命令set fileencoding来查看。


数据去重:
虽说要尽量避免对原始数据做改动,但es导入数据后再去重实在是太麻烦了,我并没有找到合适的方法,所以去重的步骤就放在清洗数据这一步了。
使用linux命令:sort -u 原文件 > 新文件 进行去重,去重后会打乱原始数据的顺序,如果顺序很重要的话不要用这个命令,可以去找一下大文件去重的python脚本。
实测sort命令处理10G数据需要15min。
最后一行数据丢失问题:
logstash导入数据时不会导入最后一行数据,所以要确保最后一行是空行。
使用linux命令tail -n 1 源文件 来查看最后一行是不是空行。
显示如下图是有空行的,可以放心导入

显示如下图是没有空行,直接导入会导致最后一行数据丢失

这时用命令echo "" >> 1.txt 就可以在文件最后添加一个空行。
2、编写logstash配置
logstash的配置文件分为三部分:input、filter和output,分别对应数据的输入、处理、和输出。
大家可以直接套用我写好的这个,使用时需要更改的部分:
(1)input—file方块里的path和codec,即源文件位置和编码
(2)output—elasticsearch方块中index的值,即导入数据到es的哪个索引(没有会自动创建)
input{file{path => "/tmp/1.txt"start_position => "beginning"codec => plain{charset => "GB2312"}}}filter{mutate{remove_field => ["host","@version","@timestamp","path"]}}output{stdout{codec => rubydebug}elasticsearch{hosts => "127.0.0.1:9200"index => "test"}}
一些问题:
文件路径问题:源文件路径处,windows和linux系统一样使用一个正斜杠
给数据添加固定字段:input中的file大方块添加add_field => {"字段名"=>"字段值"}
关于ignore_older:网上说导入旧数据要设为0,但我实测发现设为0后还是无法导入旧数据,于是干脆去掉了这个配置项。
去除ES自带的字段:在filter中添加的代码的作用,否则elasticsearch会自动添加很多没有用字段,占用空间。
ANSI编码中文乱码:input中的file大方块添加codec => plain{charset => "GB2312"}
index的命名规范:不能使用大写字母,可以用中文。不能以+、-、下划线开头,不能包含空格及各种特殊符号(包括.),长度不能超过255字符
字段命名规范:配置文件中不指定字段则自动创建名为message的字段。不能用空格,尽量不要用点号(仅用于对象类型)。
3、运行logstash入库
配置文件写好后,保存到一个位置(我这里保存到logstash安装目录的config目录下),然后在logstash安装目录的bin目录下运行命令即可开始导入数据:
./logstash -f ../config/xxx.conf

导入完logstash仍会监听文件新写入内容,不会主动退出,所以看它不动了之后要手动退出
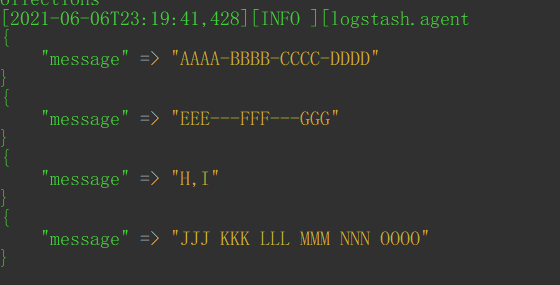
重复导入同一个配置文件:要删除logstash安装目录\data\plugins\inputs\file目录下的缓存,或在input中的file大方块添加sincedb_path => "/dev/null" (仅限linux,windows写空值会报错),否则缓存文件存在时,之前已导入过的数据不会再重复导入,做测试时要注意这一点。

数据存放位置:存放在elasticsearch配置文件中指定的data目录,删除索引会删除数据,实测入库后数据比原始数据大3.5倍。
关于导入速度:挂机导入时要注意电源设置,设置为从不睡眠,否则电脑睡眠后会影响导入性能。实测导入速度大概2kw条/h。

4、使用kibana查看数据
导入数据后如何查询数据呢,这时要用到kibana。
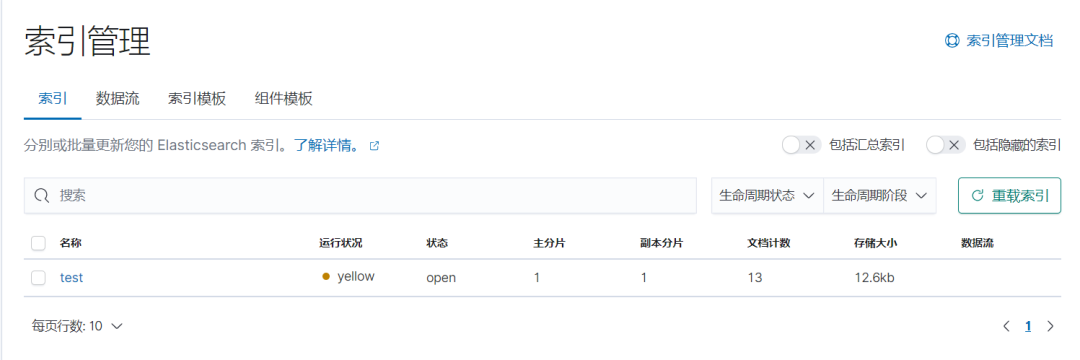
(1)kibana——左侧菜单——Stack Management——索引管理——查看数据是否完整导入(使用linux命令:wc -l 源文件查看文件行数,和这里的文档计数相对应)
(2)索引模式——创建索引模式——和索引同名
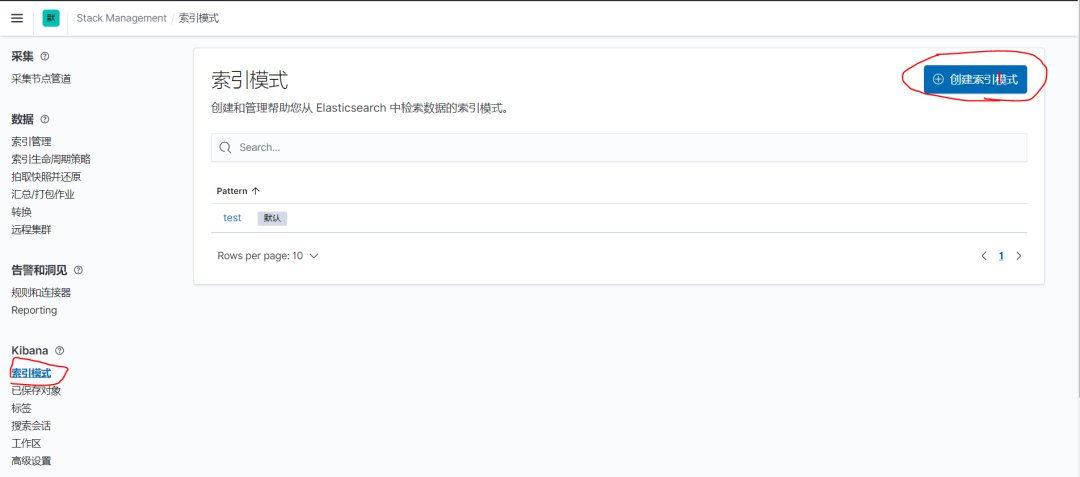
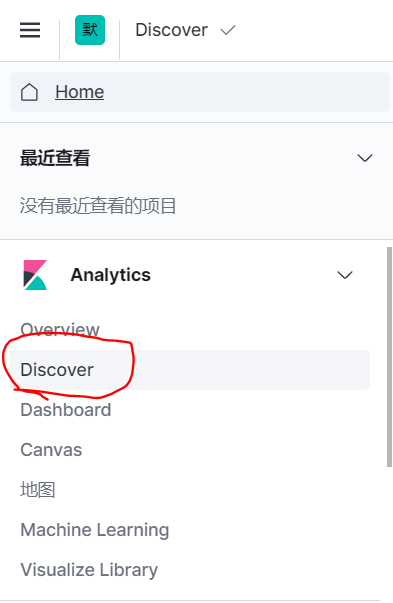
(3)kibana——左侧菜单——DisCover——进入查询界面
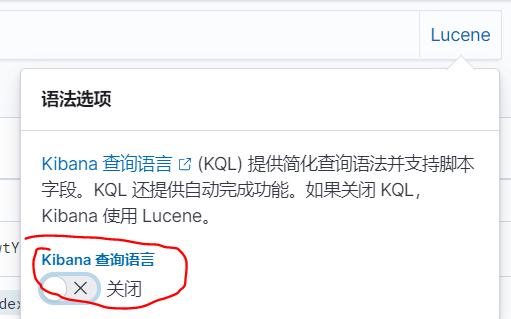
(4)点击搜索框右边的KQL切换为Lucene,否则匹配值权重可能还没有无关数据权重高
(5)在搜索框即可查询数据,尽量不要使用通配符,尤其是前置通配符,查询代价极高,可能直接把es节点打挂。
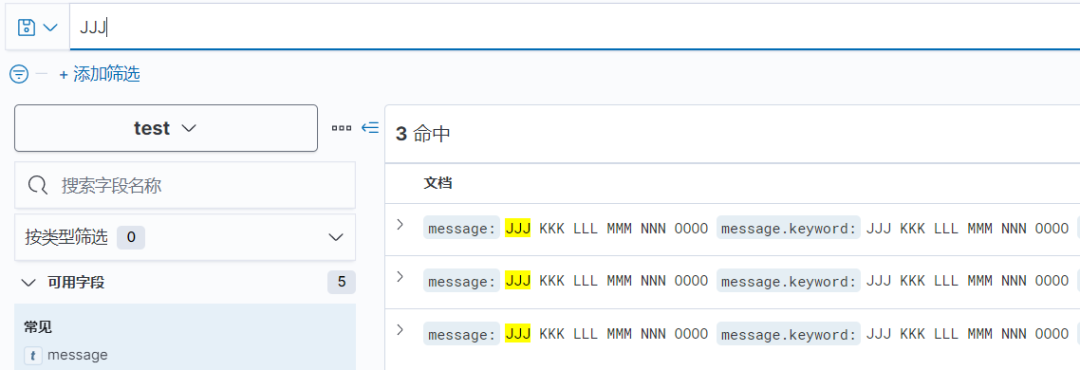
在Discover处查询没有超时时间,会一直转圈到查询出结果为止。实测查询速度和查询出的数据条数正相关,在5亿数据中查一条数据只要不到1秒,如果把5亿数据全部查出来大概要4分钟。
5、使用开发工具执行查询
kibana——左侧菜单——开发工具
批量修改数据,将匹配到字段名1=值1的数据的字段名2修改为值2(字段名12可相同):
POST 索引/文档名/_update_by_query{"query": {"match": {"字段名1":"值1"}},"script": {"inline": "ctx._source['字段名2'] = '值2'"}}
批量删除数据,将匹配到字段名1=值1的数据删除:
POST 索引名/_delete_by_query{"query":{"match":{"字段名1":"值1"}}}
还有更多的语句大家自行研究吧。
要注意这里的查询是有超时时间的,不同于Discover,对大量数据进行操作会出现502状态码,但这时查询仍在进行,注意不要同时发出多个查询请求,有可能把es节点打挂。
0x05、ELK性能优化
关于索引和分片:
(1)es本身有一些指标限制:单个分片数据容量官方建议不超过 50GB,合理范围是 20GB~40GB 之间;单个分片数据条数不超过约 21 亿条;
(2)一个索引默认5个分片,创建后不能更改,想更改需要重建索引。。
(3)索引分片过低或过多都会降低效率,需要不断调试找出针对当前索引的最优分片数量。
(4)一个大索引比多个小索引效率更高。
修改分配内存:
(1)es安装后默认使用1G内存
(2)修改es安装目录的jvm.options文件,去掉-Xms4g和-Xmx4g前面的注释和空格,调整后面的数字4g即可修改分配内存,两个值要相同。
(3)建议分配物理内存的一半(另一半会被lucene使用),但是不要超过32G。修改后重启es。
禁用内存交换:
修改elasticsearch.yml,添加一行 bootstrap.memory_lock: true
0x06 后记
如果对你有帮助,就点个赞吧~
0x07 参考文献
简单介绍ELK 组件与历史
https://www.linuxprobe.com/elk-jieshano.html
说说 ELK 火热的原因?
https://zhuanlan.zhihu.com/p/79011122
You know, for search--带你认识Elasticsearch
https://elasticsearch.cn/article/13564#tip5
ELK搭建教程(Elasticsearch+Logstash+Kibana)
https://www.jianshu.com/p/4304e60353f4
Windows 10安装Elasticsearch-7.0.0
https://gobea.cn/blog/detail/M5X2Wj6d.html
Ubuntu安装jdk11
https://www.jianshu.com/p/1658c52445fd
kinaba 安装踩坑:FATAL Error: [elasticsearch.url\]: definition for this key is missing
https://www.cnblogs.com/miaoying/p/11639437.html
linux安装elasticsearch及遇到的各种问题
https://www.cnblogs.com/cnsdhzzl/p/9401829.html
ElasticSearch启动报错,bootstrap checks failed解决方案
https://www.jianshu.com/p/ac5816776204
ElasticSearch: Index 和 Type 的区别
https://www.bayescafe.com/database/elasticsearch-using-index-or-type.html
Elasticsearch核心技术(2)--- 基本概念
https://www.cnblogs.com/qdhxhz/p/11448451.html
ElasticSearch系列(七)es内存大小设置
https://blog.csdn.net/csdn_20150804/article/details/107917560
Elasticsearch 合理内存分配
https://blog.csdn.net/choulao8648/article/details/100745746
ES 的跨索引查询有多便利?对比下分库分表、分片更直观
https://www.infoq.cn/article/ekygoihkqifj4kdgso6a
从 10 秒到 2 秒!ElasticSearch 性能调优
https://zhuanlan.zhihu.com/p/55092525


