- A+
希望文章对你有所帮助,尤其是web爬虫初学者和NLP相关同学。当然你也能,懂的~
目录:
- 0 前言
- 1 lantern访问中文维基百科
- 2 Selenium调用Chrome自动访问维基百科
- 3 Selenium爬取维基百科信息
代码及软件下载地址:
http://download.csdn.net/detail/eastmount/9422875
0 前言
在对海量知识挖掘和自然语言处理(Natural Language Processing,简称NLP)中会大量涉及到三大百科的语料问题,尤其是中文汉字语料问题,包括:百度百科、互动百科和维基百科。其应用涉及命名实体(Named Entity,简称NE)消歧、实体对齐、双语机器翻译、推荐系统、情感分析、知识图谱等领域。
其中三大百科准确率方面是维基百科>互动百科>百度百科;中文涉及实体内容是百度百科>互动百科>维基百科。如下图所示,维基百科Wikipedia页面通常包括:Title(标题)、Description(摘要描述)、InfoBox(消息盒)、Categories(实体类别)、Crosslingual
Links(跨语言链接)等。
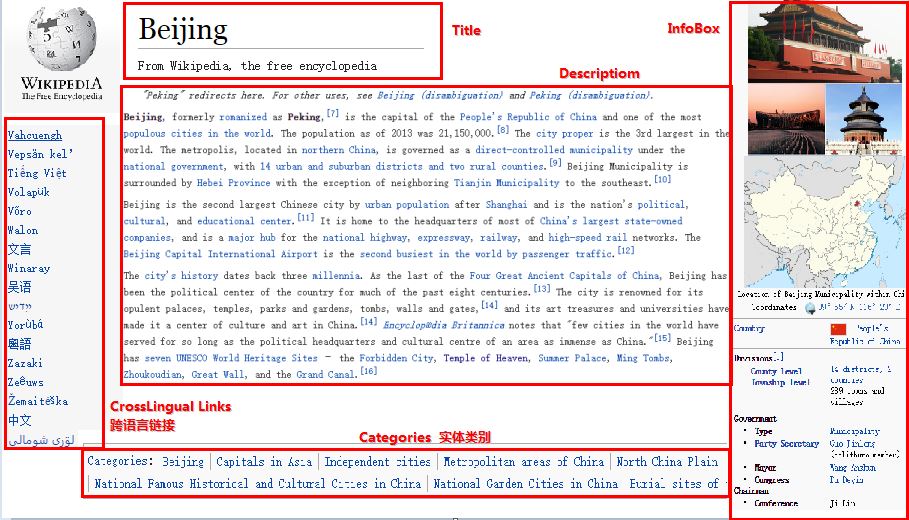
前面我讲述了很多关于Python和Selenium爬取百度百科InfoBox、生物医疗PubMed、虎扑图片的例子,虽然效率不高,但是勉强能够进行。同样你可以通过Selenium爬取自己实验的语料,设置不同的主题,再进行文本聚类、LDA主题分布、实体消歧等。
但问题来了:中文维基百科总是被屏蔽,第一个问题就是如何访问中文维基百科呢?
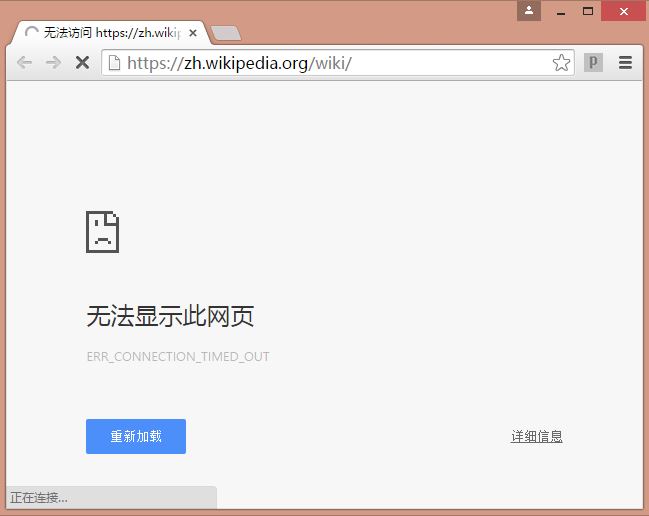
1 lantern访问中文维基百科
官文网址:https://www.getlantern.org/
参考文章:http://www.iyaxi.com/2015-11-17/732.html
下载地址:http://pan.baidu.com/s/1hrgqgGc
Lantern:一款免费强大的帆樯软件,译为“灯笼”。点击exe即可运行,非常巧小的一款软件;据说是google公司推出的,但确实良心制作。

安装运行后,会跳出如下页面:http://127.0.0.1:16823/
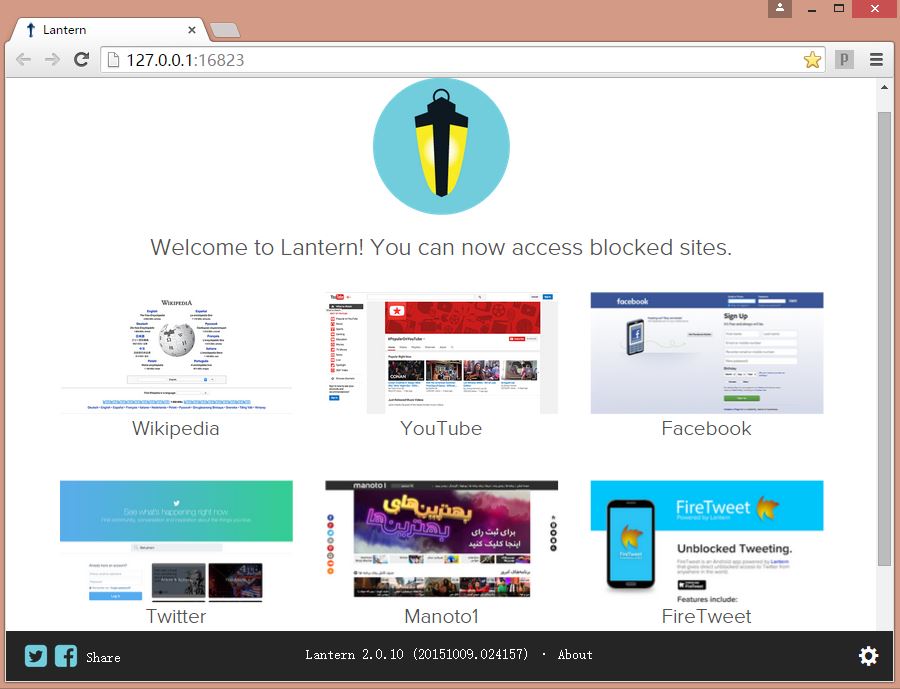
同时你可以访问YouTube和维基百科了,就是这么简单~
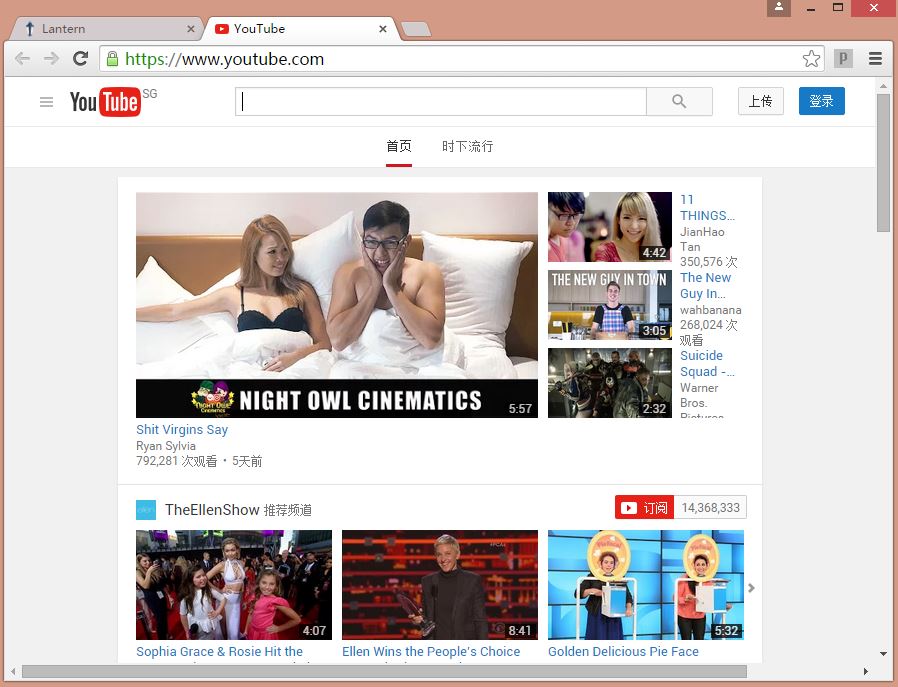
2 Selenium调用chrome自动访问维基百科
Selenium调用Firefox浏览器直接设置代码"driver = webdriver.Firefox()"即可,但是调用Chrome需要下载chromedriver.exe驱动。同时放置于Chrome安装目录下:
参考:http://download.csdn.net/download/qianaier/7966945
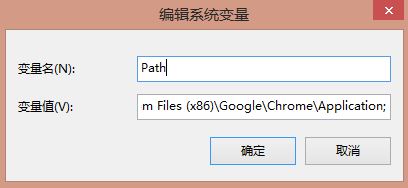
我的目录:C:\Program Files (x86)\Google\Chrome\Application,如果你报错:

同时添加该路径到环境变量path中:
下面简单四句代码即可调用浏览器自动访问维基百科页面:
[python] view plain copy

- from selenium import webdriver
- driver = webdriver.Chrome()
- url_path = "https://zh.wikipedia.org/"
- driver.get(url_path)
3 Selenium爬取维基百科内容
爬取的方法与前面百度百科的方法类似,现在txt中定义实体名称,即需要爬取的网页名称,再去到具体页面爬取内容。这里需要讲述一个方法:
https://zh.wikipedia.org/wiki/阿富汗
可以访问中国页面,同样该方法适用于互动百科,即:url+文件中读取实体名称
当然百度百科,你只需要获取输入框的按钮信息,然后输入读取文件名称,自动回车或点击即可。其中你可能会遇到一些存在歧义的页面,再处理下即可。同时维基百科和互动百科中存在分类页面,归纳了自己想要的内容,也比较方便。
最后是代码及运行结果:
[python] view plain copy
- # coding=utf-8
- """
- Created on 2016-01-30 @author: Eastmount
- """
- import time
- import re
- import os
- import sys
- import codecs
- from selenium import webdriver
- from selenium.webdriver.common.keys import Keys
- import selenium.webdriver.support.ui as ui
- from selenium.webdriver.common.action_chains import ActionChains
- driver = webdriver.Chrome()
- wait = ui.WebDriverWait(driver,10)
- #Get the infobox
- def getInfobox(name, fileName):
- try:
- print u'文件名称: ', fileName
- info = codecs.open(fileName, 'w', 'utf-8')
- print name.rstrip('\n')
- driver.get("https://zh.wikipedia.org/wiki/"+name)
- info.write(name.rstrip('\n')+'\r\n') #codecs不支持'\n'换行
- #print driver.current_url
- #爬取文本信息 共10段信息
- elem_value = driver.find_elements_by_xpath("//div[@id='mw-content-text']/p")
- num = 0
- for value in elem_value:
- print value.text
- info.writelines(value.text + '\r\n')
- if num>=9:
- break
- num+=1
- time.sleep(1)
- except Exception,e: #'utf8' codec can't decode byte
- print "Error: ",e
- finally:
- print '\n'
- info.close()
- #Main function
- def main():
- #By function get information
- path = "WikipediaSpiderSpots\\"
- if os.path.isdir(path):
- shutil.rmtree(path, True)
- os.makedirs(path)
- source = open("Tourist_country_5A_Wiki.txt", 'r')
- num = 1
- for entityName in source:
- entityName = unicode(entityName, "utf-8")
- if u'阿富汗' in entityName:
- entityName = u'阿富汗'
- name = "%04d" % num
- fileName = path + str(name) + ".txt"
- getInfobox(entityName, fileName)
- num = num + 1
- print 'End Read Files!'
- source.close()
- driver.close()
- if __name__ == '__main__':
- main()
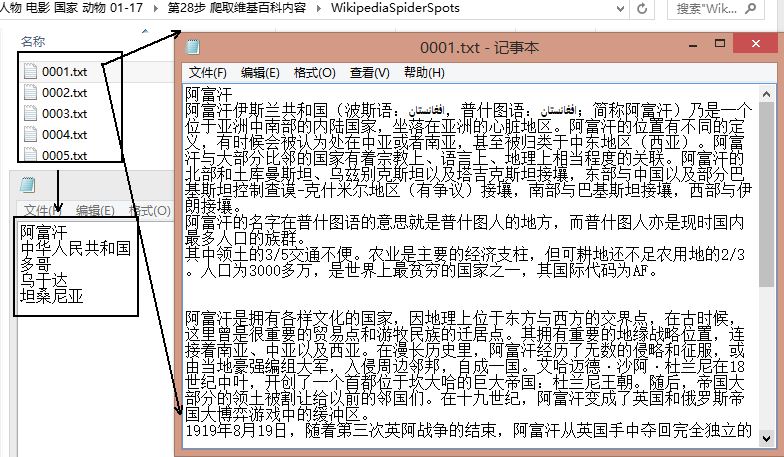
运行结果如下图,共爬取了每个实体的10段信息,而百度摘要会有id,可只爬取摘要。
同样,你也可以通过下面这部分代码爬取InfoBox信息,首先给出html源码标签:
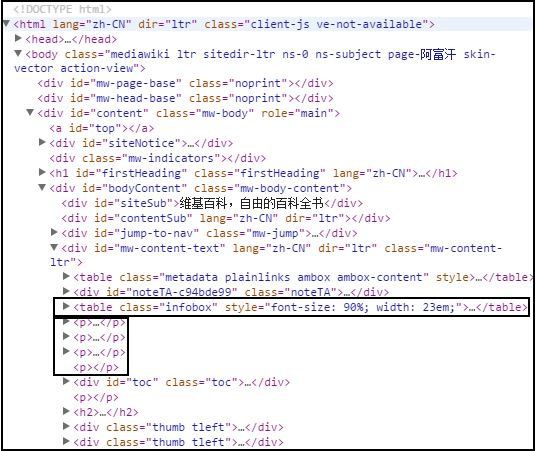
核心代码:
elem_value = driver.find_elements_by_xpath("//table[@class='infobox']")
具体代码如下:
[python] view plain copy
- # coding=utf-8
- """
- Created on 2016-01-30 @author: Eastmount
- """
- import time
- import re
- import os
- import sys
- import codecs
- from selenium import webdriver
- from selenium.webdriver.common.keys import Keys
- import selenium.webdriver.support.ui as ui
- from selenium.webdriver.common.action_chains import ActionChains
- driver = webdriver.Chrome()
- wait = ui.WebDriverWait(driver,10)
- #Get the infobox
- def getInfobox(name, fileName):
- try:
- print u'文件名称: ', fileName
- info = codecs.open(fileName, 'w', 'utf-8')
- print name.rstrip('\n')
- driver.get("https://zh.wikipedia.org/wiki/"+name)
- info.write(name.rstrip('\n')+'\r\n') #codecs不支持'\n'换行
- #print driver.current_url
- #爬取文本信息 共10段信息
- elem_value = driver.find_elements_by_xpath("//table[@class='infobox']")
- for value in elem_value:
- print value.text
- info.writelines(value.text + '\r\n')
- time.sleep(1)
- except Exception,e: #'utf8' codec can't decode byte
- print "Error: ",e
- finally:
- print '\n'
- info.close()
- #Main function
- def main():
- #By function get information
- path = "WikipediaSpiderSpots\\"
- if os.path.isdir(path):
- shutil.rmtree(path, True)
- os.makedirs(path)
- source = open("Tourist_country_5A_Wiki.txt", 'r')
- num = 1
- for entityName in source:
- entityName = unicode(entityName, "utf-8")
- if u'阿富汗' in entityName:
- entityName = u'阿富汗'
- name = "%04d" % num
- fileName = path + str(name) + ".txt"
- getInfobox(entityName, fileName)
- num = num + 1
- print 'End Read Files!'
- source.close()
- driver.close()
- if __name__ == '__main__':
- main()
运行结果如下图所示:
最后希望文章对你有所帮助,还是那句话:如果刚好你遇到这个问题,就会受益匪浅;否则感觉没什么技术含量,不过确实也挺简单的,但是灯笼还是非常强大的。一月份终于要结束了,不知道多少个熬夜到早上10点,回家好好享受下生活吧~
(By:Eastmount 2016-01-30 早上8点 http://blog.csdn.net//eastmount/ )




{kind=link}