- A+
所属分类:python笔记
参考文献:
1、https://blog.csdn.net/a745233700/article/details/80175883
大概顺序:
1、下载验证码图片
2、用PIL库将验证码图片放大,太小的图片识别不了,from PIL import Image
import pytesseract
from PIL import Image
#####For CentOS 7 run the following as root:
#####yum-config-manager --add-repo https://download.opensuse.org/repositories/home:/Alexander_Pozdnyakov/CentOS_7/
#####sudo rpm --import https://build.opensuse.org/projects/home:Alexander_Pozdnyakov/public_key
#####yum update
#####yum install tesseract
#####yum install tesseract-langpack-deu
def ocr(img_path):
img = Image.open(img_path)
thumb = img.resize((420, 180))
img_gray = thumb.convert('L')
# img_gray.save('code_gray.png')
# 转成黑白图片
img_black_white = img_gray.point(lambda x: 0 if x > 200 else 255)
img_black_white.save('img_black_white.png', quality=100)
testdata_dir_config = '--tessdata-dir "./tessdata"'
textCode = pytesseract.image_to_string(img_black_white, lang='训练完的数据集', config=testdata_dir_config)
# 去掉非法字符,只保留字母数字
textCode = re.sub("\W", "", textCode)
print textCode
return textCode
3、大坑:在合并TIF文件完了,生成.box文件后,如果标记图片时有字符不能出现坐标值,说明该张图片识别不了,赶紧把该图删除,然后重新合并TIF,否则标记完了也无法进行下一步。
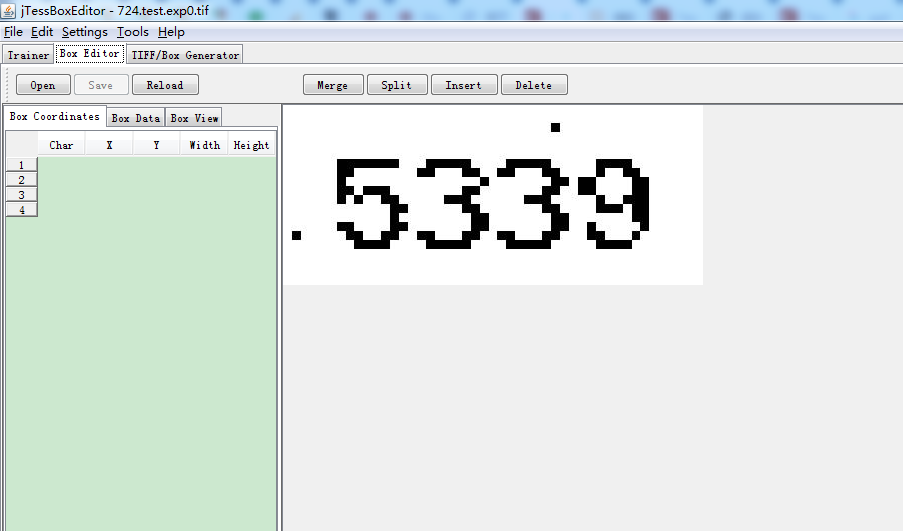
手动标记完成后,逐条输入下面的命令来生成最终的训练集
echo "test 0 0 0 0 0" >font_properties tesseract zwp.test.exp0.tif zwp.test.exp0 nobatch box.train unicharset_extractor zwp.test.exp0.box shapeclustering -F font_properties -U unicharset -O zwp.unicharset zwp.test.exp0.tr mftraining -F font_properties -U unicharset -O zwp.unicharset zwp.test.exp0.tr cntraining zwp.test.exp0.tr rename normproto zwp.normproto rename inttemp zwp.inttemp rename pffmtable zwp.pffmtable rename shapetable zwp.shapetable combine_tessdata zwp.
最后将生成的zwp.traineddata 拷贝到相应目录调用,关键代码如下:
def ocr(img_path):
img = Image.open(img_path)
thumb = img.resize((940, 400))####放大验证码
img_gray = thumb.convert('L')
# img_gray.save('code_gray.png')
# 转成黑白图片
img_black_white = img_gray.point(lambda x: 0 if x > 200 else 255)
img_black_white.save('724img_black_white.png', quality=100)
# testdata_dir_config = '--tessdata-dir "C:\\Program Files (x86)\\Tesseract-OCR\\tessdata"'
testdata_dir_config = '--tessdata-dir "./tessdata"'
textCode = pytesseract.image_to_string(img_black_white, lang='zwp', config=testdata_dir_config)
textCode = re.sub("\W", "", textCode)### 去掉非法字符,只保留字母数字
print textCode
return textCode



