- A+
我们为什么要切分?
说到切分(segmentation),大多数人最容易想到的就是中文分词。作为没有天然空格区分的语言,切词可以帮助计算机去索引文章,从而便于信息检索等方面。该部分主要用到了分词的一个方面:降低搜索引擎的性能消耗。我们常用的汉字有5000多个,常用词组是几十万个。在倒排索引中,如果用每个字做索引的话,那么会造成每个字对应的拉链非常长。所以我们一般会用词组来代替单个汉字建立索引。除此,切词更重要的一个功能是帮助计算机理解文字,在这个层次上,切词是不分语言的,任何一个语言,涉及到计算机去“理解”的时候,首先要做的,就是先去切分并在一定程度上消除歧义。这是因为,我们知道计算机本身擅长做的工作就是匹配计算。假设我们可以把每个字词都指向一个语义,当输入一个句子的时候,每个字对应语义的累加要弱于词组语义的累加(因为单独用字语义累加的时候,有个潜在的假设是字和字之间是独立的),现在引入切分目的就是勾勒出字与字之间的关系,从而让计算机更好的理解。
切分的难点在哪里?
简单的讲,评价切分效果可以从三个层次来判定:切分边界,切分片段,整个句子切分结果是否正确。切分边界是指:相邻的token(在中文切分中token可以认为是汉字,在英文中可以认为是单词)之间是否应该被切开;句子级别是指,整个句子的切分结果是不是完全准确。切分片段是介于二者之间一种评估策略: 1. 切分结果片段中是否召回了需要切出的片段(recall); 2. 切分的结果中是否有错误的切分结果(precision)。下面我们从切分算法两个重要的考量标准来阐述切分的难点,即新词识别和歧义性的处理。
新词:切分算法在召回方向上的难题主要为歧义现象和新词的出现。如果一个切分算法无法识别新词从而导致其未召回,最后会影响计算机对该切分句子的理解。前面我们有讲,字到词的过程可以让计算机“假装”理解这个词的意思。比如最近的一个人名新词“位菊月”,如果被切分算法切散后,计算机很难理解这个片段的含义,从而导致在诸如机器翻译等应用中无法准确进行处理。
歧义性:切分算法要求解决切分片段歧义性,切分结果合理。汉字作为表示中文信息的载体,假设每个字/词表示的信息有个上限,假设每种语言总体的信息量接近,由于常用字数有限,这些汉字之间就要有较多的组合形式来成词并表达不同的语义。如果一个汉字可以同时作为2个词的部分,当这2个词按序出现时,就潜在包含了歧义。目前歧义主要分为2种:交叉型歧义,即相邻歧义片段之间有若干token重复,比如“长春市长春药店”,“长春市”与“市长”“长春”与“春药”都是交叉型歧义片段。该歧义现象存在于任何语言的切分过程,比如针对英文,“new york times square”中的”new york times” 和”times square”;还有一种歧义为覆盖型歧义,即token序列在不同语义下需要拆分开或合并在一起,比如“他马上就来”和“他从马上下来”,对后者来讲,切分为“马上”时则导致“从马背上”的意思被“立刻的”意思所覆盖。
除此,切分算法在应用中还要具备不错的性能,在引入统计学习算法时,还要考虑人力在标注语料上面的成本。随着时间的发展,语言也会进行相应的变化,只是在不同的领域会按照不同的速度演变着。因此,切分算法同样需要与时俱进的优化。比如添加更多的词进入词典,更新重建语言模型(Language Model), 对于某些基于判别式(Discriminative model)切分的方法,比如CRFs,需要不定期更新人工标注语料来使得切分算法适应处理当前语料等等。
切分算法作为一个基础的研究方向一直是很多科研人员努力奋斗方向,并产生出大量优秀的算法。在下面的章节中,我们简单的介绍一些主流的、在工程中有着一定应用的切分方法。
切分的主流方法简介
在介绍我们的切分方法之前,我们先从2个方面来简单介绍现有主流切分算法:即基于规则的切分方法和一些统计切分模型。
1.基于规则的切分方法。
基于规则的的切分方法主要表现为基于词典匹配,如:正向最大匹配(Forward Maximum Matching, FMM),逆向最大匹配,最少切分(使每一句中切出的词数最小)等等。
以正向最大匹配为例,其基本思想是:对于待处理文本,从左到右尽量匹配词典中的最长词,匹配到的词即该处理文本的一个切分片段。假设词典中有{百度,百度公司,中文,切分,算法}5个词,则句子“百度公司的中文分词算法”的正确切分结果为“百度公司|的|中文|分词|算法”。
基于规则匹配的切分算法,缺点主要有2点:(1).无法很好的解决切分歧义问题。上述提到的三种方法都是从不同的角度尝试去解决歧义问题,但是它们对于歧义消除的效果不显著,特别当词典词增多的时候,词与词之间交叉现象加剧,该方法的歧义处理能力就会相应的减弱。(2).该方法无法识别新词。在该方法下,线下挖掘大量的新词加入词典的收益和整体效果并非线性关系,词典膨胀的同时,切分的歧义现象会更加严重。
由于该方法简单快捷,因此针对上述缺点也有一些工作是将统计方法用在FMM上,该类方法主要运用贝叶斯模型(Naïve Bayes)、互信息(Mutual Information)以及t-test chi-2等检验手段对有切分歧义的相邻片段进行消岐。这方面可以参考“基于无指导学习策略的无词表条件下的汉语自动分词”等文献。
2.统计切分模型
统计切分算法主要利用语言模型、标注数据等资源,根据切分假设建立模型并利用其对应的资源进行模型参数优化,借助模型代替规则完成切分。
2.1 基于语言模型、Markov链的切分方法
对于一个待处理的句子![]() 其每个处理的token(t_i,在中文分词中可以认为是汉字,在英文中可以认为是单词等)构成一个观察序列,各种可能的切分片段即为隐含的状态。该方法的目的即为观察序列找一个最有可能发生的隐含状态序列
其每个处理的token(t_i,在中文分词中可以认为是汉字,在英文中可以认为是单词等)构成一个观察序列,各种可能的切分片段即为隐含的状态。该方法的目的即为观察序列找一个最有可能发生的隐含状态序列![]() 其中每个状态status(s_i)即为词典词。整个切分过程即为了寻找一个可行的切分结果
其中每个状态status(s_i)即为词典词。整个切分过程即为了寻找一个可行的切分结果![]() 利用markov假设,使得达到maximum likelihood:
利用markov假设,使得达到maximum likelihood:
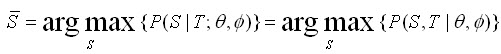
如果有了词典词的各种概率分布(可以通过利用语言模型进行极大似然估计,利用EM算法进行参数优化等得到),根据viterbi解码算法,很容易就得到了切分结果。随着语言模型的广泛应用,以及各种learning算法的发展,该方法也具有广泛的应用场景。深入阅读的可以参考以下两篇文章:《Self-supervised Chinese word segmentation》,《unsupervised query segmentation using generative language models and wikipedia》。
现在说说该方法的不足:1. 在计算序列![]() 的概率时,我们依据markov假设,即:当前状态仅仅和前面一个状态相关。而在我们实际应用中,当前的状态可以和前面状态有关系,也可以和前面的前面状态有关系,也可以不和前面的状态有关系等等(这里面的是否有关系是在一定阀值条件下说的)。2. 在估算词典词之间的概率分布时,EM作为一个常用的算法也有自身的不足。
的概率时,我们依据markov假设,即:当前状态仅仅和前面一个状态相关。而在我们实际应用中,当前的状态可以和前面状态有关系,也可以和前面的前面状态有关系,也可以不和前面的状态有关系等等(这里面的是否有关系是在一定阀值条件下说的)。2. 在估算词典词之间的概率分布时,EM作为一个常用的算法也有自身的不足。
2.2. 条件随机场模型(Conditional Random Fields )
CRFs是一个无向图模型,它的目标是寻在在条件概率最大情况下的一种组合[Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data.]。在NLP技术领域中主要用于文本标注,应用场景主要为:分词(标注字的词位信息,由字构词),词性标注(Pos-Tagging,标注分词的词性,例如:名词,动词,助词),命名实体识别(Named Entities Recognition,识别人名,地名,机构名,商品名等具有一定内在规律的实体名词)。
它把切分的过程看作一个标注的过程,即对一个观察序列中的token进行标注,比如标记为4中状态:词首(Begin), 词中间部分(Middle),词尾(End)和单独存在(Single)。对于一个输入序列![]() 其标注序列为
其标注序列为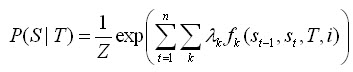 在输入序列下的条件概率:
在输入序列下的条件概率:
![]()
其中Z为归一化函数,它等于所有可行标注序列条件概率的总和。![]() 为特征函数(feature function),
为特征函数(feature function),![]() 是其对应的权重。该特征函数用来在观察序列T下,当前计算阶段i下状态序列
是其对应的权重。该特征函数用来在观察序列T下,当前计算阶段i下状态序列![]() 的情况。我们的目标是找到一个标注序列,使得上式达到最大值:
的情况。我们的目标是找到一个标注序列,使得上式达到最大值:
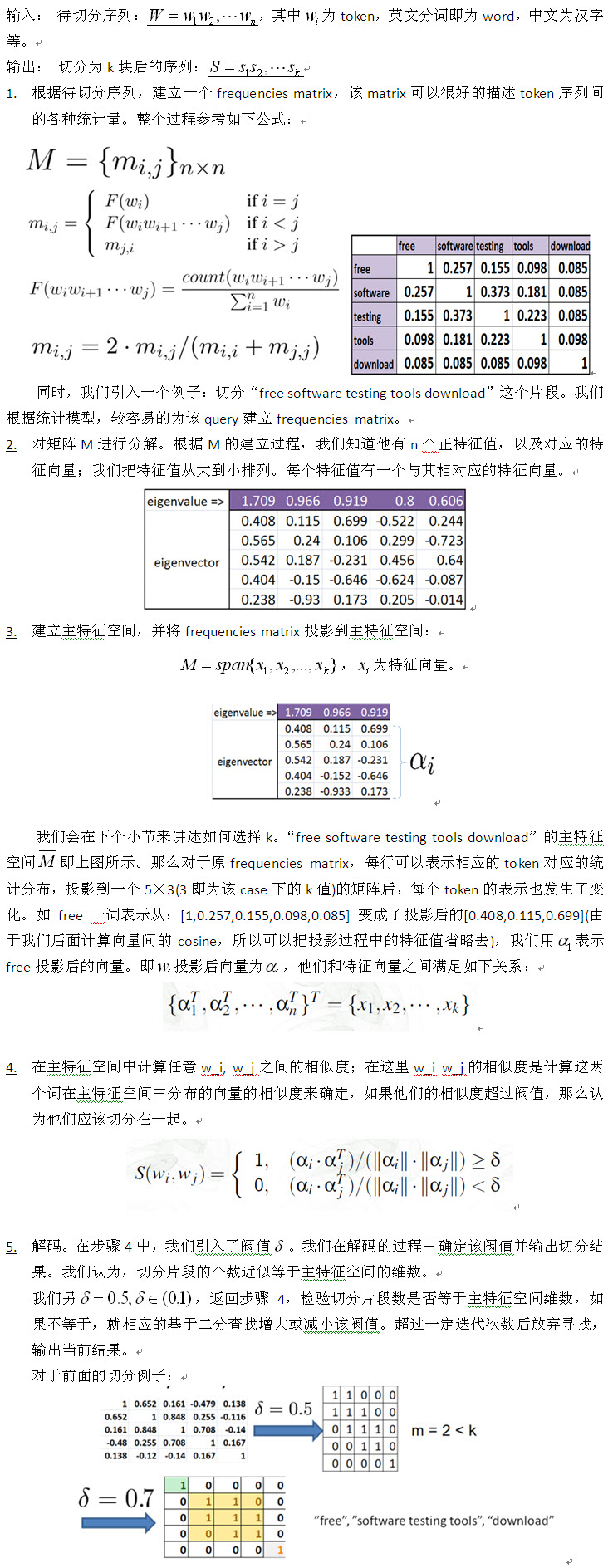
如果我们有了可以用于计算的各种概率分布,利用viterbi算法,不难获得该序列的标注情况。再根据每个token的标注状态(BMES)来进行切分。具体可以阅读这篇文章《Chinese Segmentation and New Word Detection using Conditional Random Fields》。
除此,CRF模型在中文分词上取得不错的成绩,能否直接移植到其它语言呢?语言特征和training语料间有怎样的关系时整个切分算法才能出色的运行?有兴趣的读者可以思考这个问题。
在该节中,我们主要介绍了各种切分模型的原理,分析了他们的应用场景。在下面一节中,我们介绍一种新型的算法,它利用语言模型进行切分,它的假设是:如果两个词应该切分在一起,那么这两个词,在一定的条件下分布是接近的。
基于统计语言模型的无监督切分
在本节中,我们会介绍一种新型的无监督切分算法(Query Segmentation Based on Eigenspace Similarity),相对于基于HMM(隐马尔可夫模型,Hidden Markov Model,方法备注)的方法来讲,他充分考虑了切分片段整体信息,并且在后面的章节中,我们会介绍该方法有很好的拓展性,从各个角度来讲都符合我们在最初提出的切分难点的解决。
在介绍具体算法之前,我们说说该算法的假设。对于A B两个token,他们可以切分在一起就说明他俩在一定条件下紧挨着出现,换句话说,在一定条件下(即整个待切分句子的上下文环境),他俩的数据分布是比较相似的,如果我们可以获得其数据分布(vector),再计算这两个vector之间的相似度,就可以决定这两个token是否应该合并在一起。这个方法听起来似乎和互信息(Mutual Information)有点像,但是互信息并没有考虑我们前面说的一定条件下,不过也有一些工作针对MI这点引入了cosine of point-wise mutual information。即便考虑了上下文信息,还有个问题比较棘手:判断两个token是否应该合并在一起的阀值应该是多少?在有些工作中[Generating query substitutions],这个阀值被经验地设置为一个定值,事实上,这样做可能是不大合理的。在各种各种下,我们构建了这样一个切分的上下文环境,并且巧妙地把统计特征投影到其主特征空间(principal eigenspace,在线性代数中,特征空间是由一个矩阵的所有特征向量张成的空间,主特征空间是有该矩阵的主要特征向量张成的空间。相比较特征空间,主特征空间可以覆盖特征空间大部分信息,并且可以辅助相关应用进行有效的降维、除噪和数据变换等),计算相似度,配合主特征空间的维度进行切分。
1.算法流程:
我们以一个例子来讲述该算法是如何工作的,有兴趣的读者可以阅读该文[Query Segmentation Based on Eigenspace Similarity]。(点击查看大图)
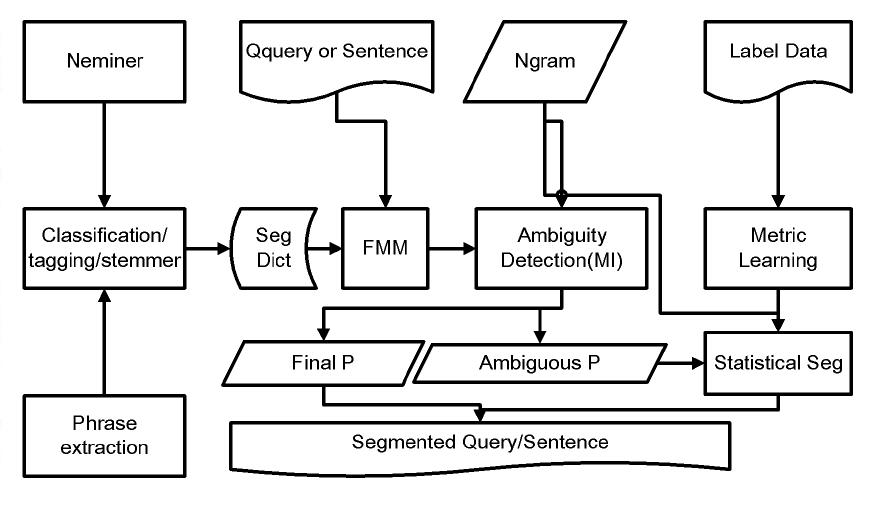
2.算法分析:
该算法一个核心的要点为主特征空间维度k的确定。换个角度讲,对于给定一个待处理串,如果事先知道切分的片段数,利用一些简单的统计策略如MI已经可以较好的做切分。
关于参数k的确定,论文中给出一种简单的判断方法。这方面也有相关的一些研究方法,有兴趣可以深入阅读谱聚类(spectral clustering)以及Principal Component Analysis, Springer (2002)一书中的第六章” Choosing a Subset of Principal Components or Variables”。
该切分算法根据数据分布入手,由切分片段特征展开假设,通过基本token在一定相关语义下统计分布而进行切分。相对基于EM/HMM等模型的无监督切分算法,该方法一个明显的优点是充分考虑了整个切分片段的信息,而不是相邻token之间的统计量;同时,该方法通过空间变换等手段,有效的进行数据除燥等策略,从而是数据分布更趋于真实情况。
同CRF等有监督学习相比,该方法的输入为ngram语言模型,不需人工标注数据 ,同时本方法可以识别新词,这在互联网应用中极具优势。同时针对不同语言不通领域,我们只要提供足够可靠的语言模型就可以在很大程度上解决他们的切分需求。
当然本方法(or无监督切分方法)在切分的准确率上和基于有监督的模型相比仍有差距,我们在下节会阐述这个问题,并给出一个我们勾画的切分体系。
如何打造一个好的切分框架?
简单的说:1. 词典是需要的,并且有有效的手段源源不断的更新词典词,在不同的应用需求下,这些词典词在切分体系中的位置和作用可能不一样。2. 强大的语言模型是需要的。原因是:如果A B两个token应该切分在一起,那么“AB”这个组合就应该在互联网中大量出现。3. 人工标注的数据也是必要的,这是因为,切分作为人们对句子一个主观的认识,这个和数据在语料中的分布不是完全一致的。
先说说有监督和无监督两种方法的差异。如果无监督的效果可以赶得上有监督的方法,那么有监督方法就可以彻底和分词说拜拜了。那么无监督方法切分效果瓶颈来源于哪里呢?这里用一个例子来解释。很多用户在在遇到不认识的字时候,会通过如下手段去搜索学习,query“**头上加一??”,如“旦头上加一横是什么字”等等,由于无监督学习是根据数据的分布出发,在这样的case中“头上加一”或者“加一”就会被切分出来。事实上,这种切分方式和人们的认识是不一样的。这是一个极端的例子,数据分布和人们主观认识不一致有很多因素。
我们在使用有监督的方法解决问题是,主要着眼点在考虑local consistency,也就是说,所有的工作是基于已经标注的数据进行开展,标注语料决定了最后的算法效果;而无监督方法更多的是从全局的数据分布(global consistency)来看,如果某个需求下数据具备全局的结构特征,则无监督模型也可以很好的对其进行解决。
那么在这里我们就有个设想,引入部分的标注数据来改变数据的原始分布,最后优化切分效果。半监督学习(semi-supervised learning)的引入即可以在很大程度上提升无监督切分的效果。我们之所以引入介绍无监督切分算法,是因为该方法可以和现有的半监督学习算法相结合。
结合上面所说的,描述一下我认为一个好的切分体系应该是什么样子。
1.我们需要词典。词典的来源有很多,比如专名挖掘(NE mining), 词组挖掘(Phrase Extraction)。同时我们还要有个模块对这些资源进行不同程度的加工,最后提供一个词典给正向最大匹配(FMM)切分使用。我们会在后续的章节中,介绍新词挖掘,资源抽取等技术。
2.我们之所以使用FMM是因为本算法可以完美地处理很多待处理语句。只有在FMM无法解决的时候,我们才会引入统计切分算法。这个时候,我们需要一个trigger来负责这件事,就如上图中的Ambiguity Detection模块。这个模块可以把一个句子分成2种形式,可以通过FMM处理的简单句,需要统计模型处理的复杂句。对于复杂句采用统计切分,最后把二者结果merge起来。
3.统计模型的方法有很多,在这里自然要推荐文中所述的模型。该模块输入为ngram语言模型。统计切分算法的优化过程是引入标注数据来改变ngram中token之间的分布。在这里,我们推荐使用metric learning的方法,直接对frequencies matrix进行改动。切分的bad case也可以通过标注数据来修复。
在这种体系下,我们很好地解决了切分过程中存在的一致性、歧义处理、新词、可持续提升、可扩展性、性能等因素。
切分作为自然语言处理中一个最底层的工作,有大量的学者在这方面进行不断的研究。在中文分词方面,清华大学的自然语言处理同学收集了这方面的论文: http://nlp.csai.tsinghua.edu.cn/~zkx/cws/bib.html,有兴趣的读者可以根据需要进行相应的扩展阅读。
百度自然语言处理在中文分词上做了相当多的工作,在后续,我们会从切词中遇到的技术和资源进行展开讨论。

