- A+
一些新创业公司的网站,由于追求时髦或是某种原因,选择了一些高大上的web框架。但某些框架只能前端渲染,即页面中的部分数据只能通过前端浏览器加载后才能调出来,然而搜索引擎蜘蛛并不是浏览器,获取的只是从后端服务器传回来的数据,没办法看到全部数据,所以spider看到的页面信息是不全的。
搞SEO常会见到这种情况,比如各种使用ajax的网站。SEO的解决办法各种各样,大部分的原理是用户和搜索引擎各设置一台服务端,用户和蜘蛛进来各返回不同的页面,当然,给蜘蛛的是已经渲染过的、有数据的页面。
本渣渣在V2EX遛弯的时候发现了这篇文章,觉得不错,于是转了过来,地址请点击左下角‘原文链接’。
PS:如果你去创业公司面试SEO岗位,别忘留意下网站用的什么框架,如果需要前端渲染才能出数据的,要他们改过来,如果他们嫌麻烦,请对他们say goodbye
前言
SEO在搜索引擎时代对于网站来讲意义重大。一个网站,不管是小站还是大站,都离不开搜索引擎的流量导入,所以,做好 SEO一直都是网站站长/开发者一门重要的功课。
在网站页面后端渲染的时代,开发者只需要按照规范制作搜索引擎友好的页面便可以快速让搜索引擎收录自己网站的各个页面。
随着前后端技术的更新,越来越多的前端框架进入开发者们的视野,网站的前后分离架构越来越得到开发者们的喜爱与认可。 后端只提供数据接口、业务逻辑与持久化服务,而视图、控制与渲染则交给前端。 因此,越来越多的网站从后端渲染变成了前端渲染,而由此带来的直接问题就是各大搜索引擎爬虫对于前端渲染的页面( 动态内容 )还无法比较完善的爬取,这就导致了网站的内容无法被搜索引擎收录,直接影响网站流量与曝光度。
博主的网站从去年五月开始也开始采用了前后分离的构架,使用了 AngularJS 框架搭建了 NewRaPo , 之后又使用 Vue.js 框架进行了整体重构 RaPo3。 无一例外,他们都是基于前端渲染的,然后在此后的一年多时间里,搜索引擎收录的页面都是这样的:
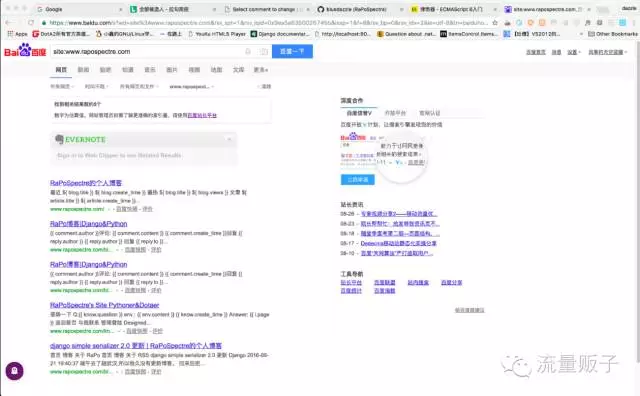
( 其他搜索引擎也一样,最早的截图已经找不到了,先拿这个应付一下 )
快照是这样的:
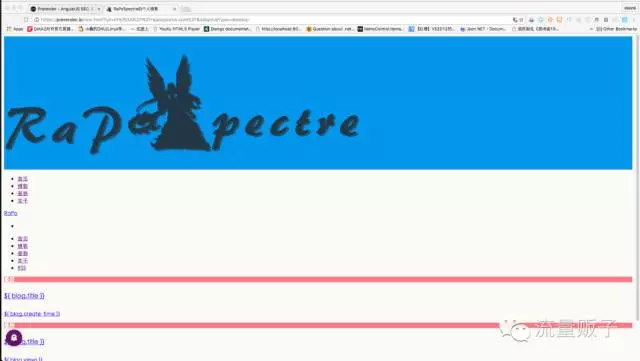
而博主实际的网站是这样的:
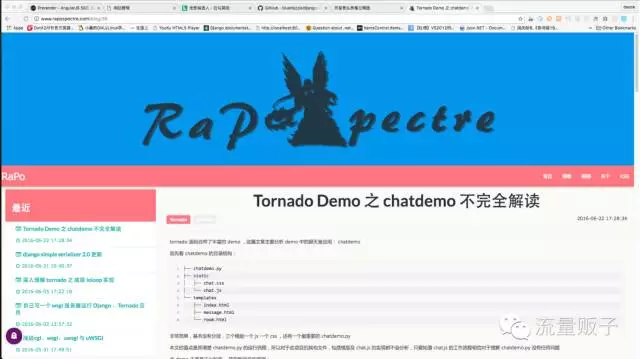
感觉完全被搜索引擎抛弃了好嘛!这东西谁能搜到啊!搜到了谁会点啊!
为了能让搜索引擎正常的收录博主的网站,于是博主踏上了动态 SEO 优化的踩坑之路:
1、fragment 标签
首先,博主 Google 到了在动态页面中加入
<meta name="fragment" content="!">
告诉爬虫这是个动态内容的页面,然后爬虫会在当前链接后面加上:
?_escaped_fragment_=tag
来获取相应页面的静态版,于是果断盘算在路由里改一下,然后重写一套后端渲染的页面返回给所有带
?_escaped_fragment_=tag
的链接。正当我高兴这个问题这么容易解决的时候突然发现网上资料都表示这个方法只有 Google 的爬虫认可,其他搜索引擎全部没用! wtf ,白高兴一场。
2、PhantomJS
PhantomJS 是一个基于WebKit的服务器端 JavaScript API 。它全面支持 web 而不需浏览器支持,其快速,原生支持各种Web标准:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG 。 PhantomJS 可以用于页面自动化,网络监测,网页截屏,以及无界面测试等
简单来说就是PhantomJS能在服务端解析html、js 。
具体怎么使用,简而言之就是判断爬虫来爬取页面的时候把每个动态页面先让 PhantomJS 跑一遍,然后把得到的静态结果返回给爬虫,具体过程可以参考:http://f2er.info/article/29
当然博主看过之后没用采用自己搭 PhantomJS 服务做动态内容优化,主要因为:
-
爬虫每访问一个页面就要让 PhantomJS 渲染一次,相当于爬虫访问一次实际服务器要响应两次,第一次响应爬虫,第二次响应 PhantomJS 自己,这种方式不仅浪费资源,而且并不优雅;
-
PhantomJS 对于新的前端技术兼容性会存在问题,可能会出现渲染失败的情况;
-
渲染页面无缓存,每访问一次就重新渲染一次,会造成网站响应速度变慢。
3、Prerender.io
Prerender.io 是一个基于 PhantomJS 开发的专为动态页面 SEO 提供静态页面渲染的在线服务,基本上解决了自己搭建 PhantomJS 服务所遇到的问题,网站配置 Prerender.io 后 Prerender 将会直接取代网站后端对爬虫请求进行响应,将提前渲染好的动态页面直接返回给爬虫。
具体配置:
-
注册 Prerender.io 账号,免费用户可以渲染 250 个页面,对于博客网站来说足够了;
-
安装中间件并设置 token ,博主直接采用了 nginx 配置方案,( Prerender.io 也提供了其他解决方案: https://prerender.io/documentation/install-middleware )博主后端服务器是 uWSGI, 根据 Prerender.io 提供的 nginx.conf 中做如下修改:
server { listen 80; server_name www.rapospectre.com; location @prerender { proxy_set_header X-Prerender-Token YOUR_TOKEN; include uwsgi_params; set $prerender 0; if ($http_user_agent ~* "baiduspider|twitterbot|facebookexternalhit|rogerbot|linkedinbot|embedly|quora link preview|showyoubot|outbrain|pinterest|slackbot|vkShare|W3C_Validator") { set $prerender 1; } if ($args ~ "_escaped_fragment_") { set $prerender 1; } if ($http_user_agent ~ "Prerender") { set $prerender 0; } if ($uri ~* "\.(js|css|xml|less|png|jpg|jpeg|gif|pdf|doc|txt|ico|rss|zip|mp3|rar|exe|wmv|doc|avi|ppt|mpg|mpeg|tif|wav|mov|psd|ai|xls|mp4|m4a|swf|dat|dmg|iso|flv|m4v|torrent|ttf|woff|svg|eot)") { set $prerender 0; } #resolve using Google's DNS server to force DNS resolution and prevent caching of IPs resolver 8.8.8.8; if ($prerender = 1) { #setting prerender as a variable forces DNS resolution since nginx caches IPs and doesnt play well with load balancing set $prerender "service.prerender.io"; rewrite .* /$scheme://$host$request_uri? break; proxy_pass http://$prerender; } if ($prerender = 0) { uwsgi_pass 127.0.0.1:xxxx; } } }
然后重启服务器,通过 Google Search Console 或其他站长工具提交页面进行爬取检测,可以看到, Prerender.io 成功截取了爬虫请求并进行了渲染:
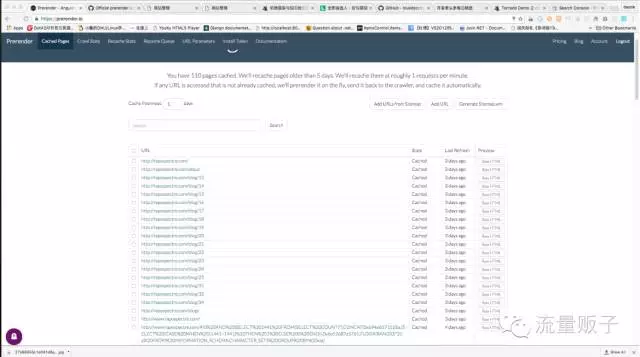
嗯,终于解决了嘛,正当博主感叹不容易的时候, Google Search Console 的抓取结果却让人发现然并卵:
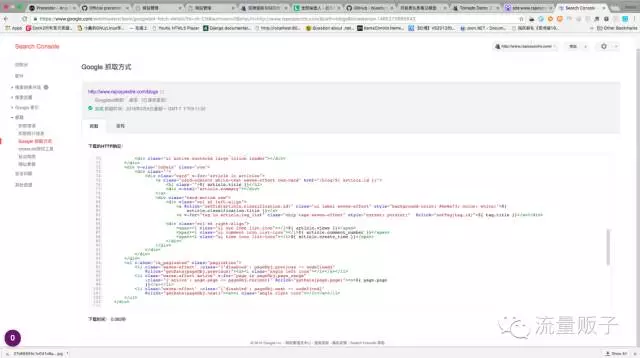
抓取的内容依然是满满的 ${ article.views }} 渲染模版,当时我认为应该是网站缓存的问题,所以没有多想,然而一周后再次测试,情况依旧,回头再看 Prerender 渲染的网页:
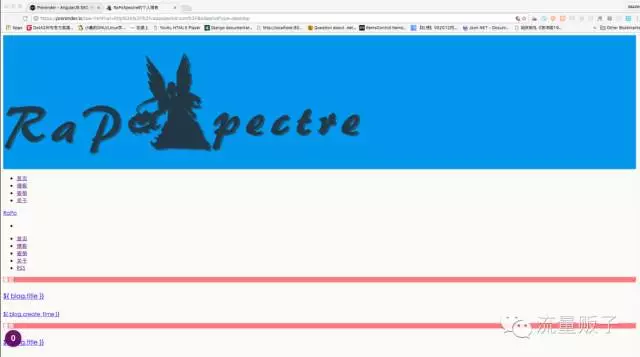
原来压根没起作用!之后又检查了配置和文档,尝试联系了 Prerender.io 的技术支持甚至向 Prerender 的 Github 提了相关 issue ,都没有解决问题。 最后,不得已博主还是放弃了 Prerender 。
4、自己搭建后端渲染服务
Prerender 的方案启发了我,通过判断来访请求的 User-Agent 来让不同的后端服务器进行响应,虽然网上关于 SEO 优化的讨论中明确提到过判断 UA 返回不同页面将会得到搜索引擎的惩罚,但我猜测这只是返回不同内容才会惩罚,如果返回的是相同的内容搜索引擎就不会进行惩罚,区别在于一个是直接通过前端渲染的页面,而另一个则是后端渲染的页面,两个页面渲染出的内容基本相同,那么搜索引擎就不会发现。
自己动手,丰衣足食,有了想法立即验证,首先把网站代码中前端渲染的部分改为后端渲染,然后 push 到一个新的分支,博主网站修改十分简单,大概只修改了 50 行不到的代码就完成了需求:RaPo3-Shadow
接着将后端渲染代码部署到服务器,然后假设用 uWSGI 将它跑在 11011 端口, 此时前端渲染的代码由 uWSGI 假设跑在 11000 端口;
最后修改 nginx 配置文件 nginx.conf :
server {
listen 80;
server_name www.rapospectre.com;
location @prerender {
include uwsgi_params;
set $prerender 0;
if ($http_user_agent ~* "baiduspider|twitterbot|facebookexternalhit|rogerbot|linkedinbot|embedly|quora link preview|showyoubot|outbrain|pinterest|slackbot|vkShare|W3C_Validator") {
set $prerender 1;
}
#resolve using Google's DNS server to force DNS resolution and prevent caching of IPs
resolver 8.8.8.8;
if ($prerender = 1) {
uwsgi_pass 127.0.0.1:11011;
}
if ($prerender = 0) {
uwsgi_pass 127.0.0.1:11000;
}
}
}就是通过 UA 判断爬虫,如果是则转发给 11011 端口,不是就转发给 11000 端口,当然两个端口返回的页面基本是相同的,所以也就不用担心会被搜索引擎惩罚了。
通过以上配置后,动态页面的 SEO 问题终于得到了解决,反应最快的是 Google ,第二天就爬取并更新到了搜索引擎:
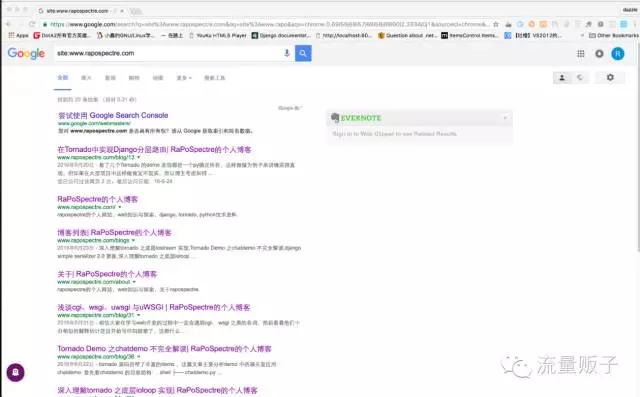
接着 360 搜索:
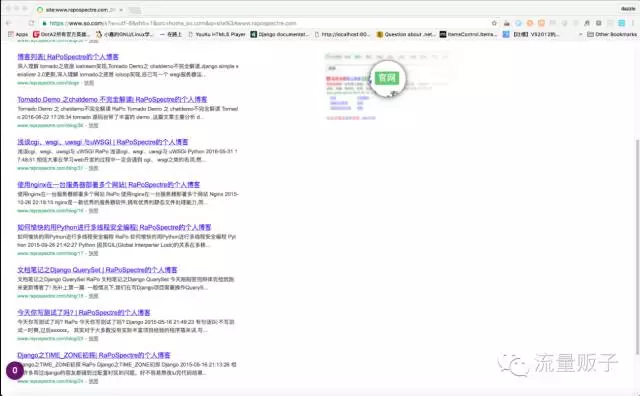
当然,不知道什么原因百度过了两个多月还是没有收录,在站长工具中提交网页甚至申诉都没有收录新的网页。没错,开头那个用来应付一下的图片就是百度的结果,刚截的。
我该说幸好没更新,否则找不到以前的例子了嘛,哈哈哈哈。



