- A+
文|.NET程序猿小伍
两周前,做的一个项目需要模拟一批用户评价数据,如果想让数据看着真实点,那就得使用随机的用户昵称和头像啊。要是头像或者昵称全都差不多,那别人一看就看出来这是做的数据了。
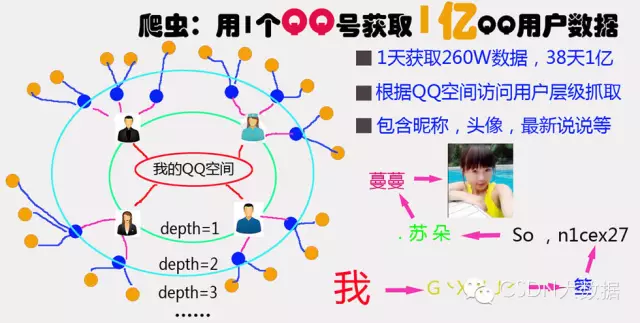
于是乎我就写了个从我QQ空间开始的蜘蛛网式的爬虫程序,程序断断续续的运行了两周。总共爬到了腾讯3000万QQ数据,其中有300万包含用户(QQ号,昵称,空间名称,会员级别,头像,最新一条说说内容,最新说说的发表时间,空间简介,性别,生日,所在省份,城市,婚姻状况)的详细数据。
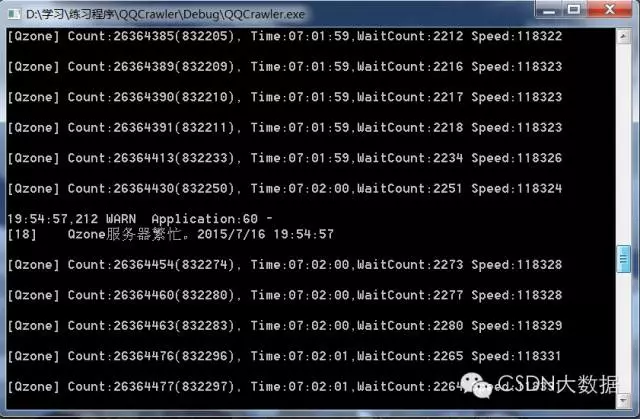
目前已经爬到我的第7圈好友(depth=7)共3000万数据,目前的瓶颈在家里的网速和电脑的配置上。最快的时候爬取速度达到一天500W新Q数据。
没图,我说个毛线啊!
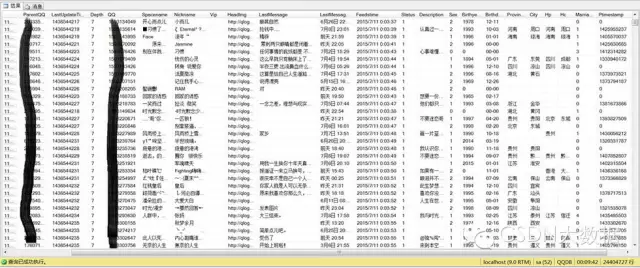
目前数据量为2G左右。
再看看,我根据这份数据生成的一些有趣的统计图(数据量太大了一次加载到内存中直接报内存不够了,所以下面的统计数据只取了depth值小数据较完整约80W的数据):
内存已经爆了,不能怪我。谁赞助台服务器吧

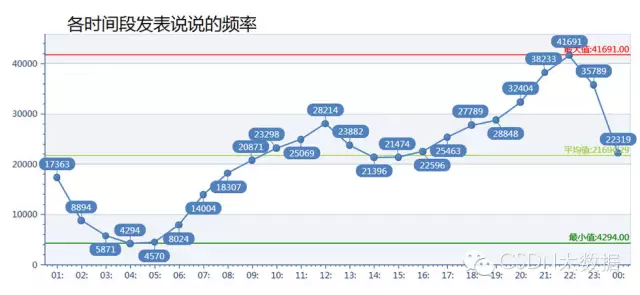
1、大家一般都在啥时候发说说呢?
从图中看出一天最冷门的时候是凌晨4点,这时全国正在睡觉的人最多。大家最亢奋的是晚上10点到11点,人们都喜欢睡前看看别人的空间,发条说说。中午12点左右也有一波小高峰
一会我再统计张中国人习惯几点起床,几点吃饭,几点睡觉的图吧
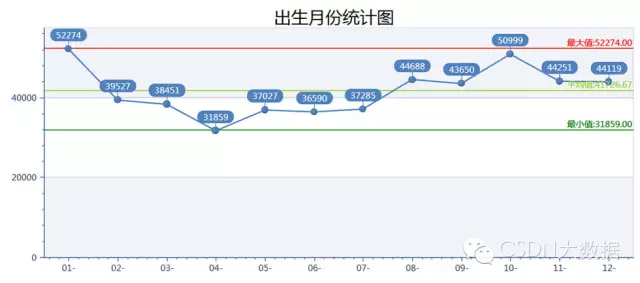
2、中国人都喜欢在几月生小孩呢?
最热门的是1月份和10月份,最冷门的是4月份。10月份生小孩的多好理解,一年忙差不多了,天气也不冷不热正是生小孩的好时候。但1月份最高且和2月落差很大有点不好理解,那么冷的天生不怕冻吗?我估计是1月份也快过年了,以前没聚一起的好不容易聚一起了,就容易冲动,冲动就啪啪啪。4月份生日的最少也好理解,中国人不喜欢4这个数字呗。大数据有意思吧!!我觉得太好玩了,后面还有很多呢。
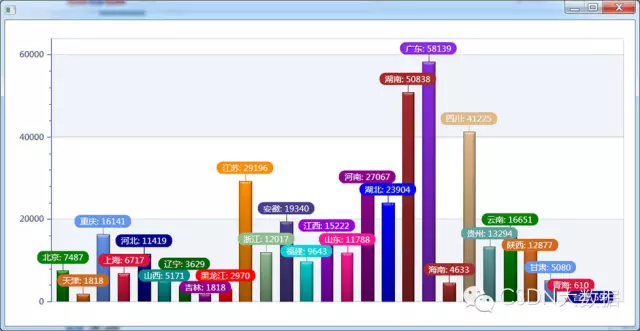
3、这是我目前爬取的用户所在地分布
你能猜出我是哪的了吗?前四名分别为:广东,湖南,四川,江苏。没错,我就是湖南的!湖南人在广东打工的超级多,这也能理解为什么广东排名第一了。江苏是我上学的地方,有点琢磨不透的是四川和我非情非故的居然排第3名,我的朋友们,你们是谁播的种?站出来!还有一种可能,四川人交际能力全国第一,我平时在重庆小面吃饭,四川人确实特别,说话语速那个快啊,声调那个高啊。受不了!
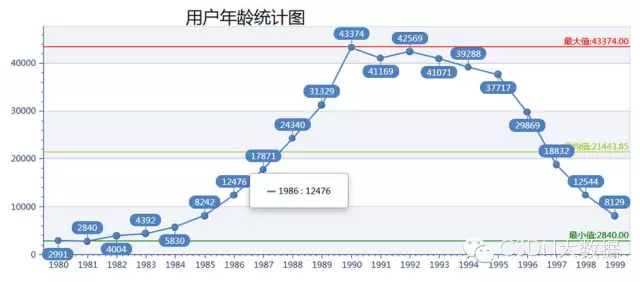
4、数据人群的年龄分布
一不小心就暴漏了我的年龄,没错。我就是那个最高值的1990年;从目前的数据来看,无论是分布地区以及年龄阶段与我的关联还非常大,随着数据量的不断增加这种关联会逐渐变小,统计图也会逐渐接近全国用户的真实情况。真想弄几台服务器分布式搞起,估计一周就能爬上亿的简单数据。单靠我的笔记本和家里超烂的网速达到这个目标还很远。
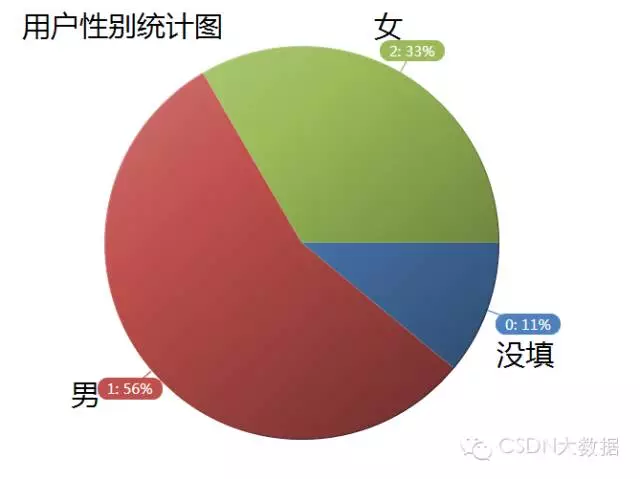
5、数据人群性别分布
男比女足足多了23%的人数,我分析认为实际差距应该是不大的,但女生在设置QQ空间访问权限时普遍要比男生的高。所以我爬取的数据中男生居多。
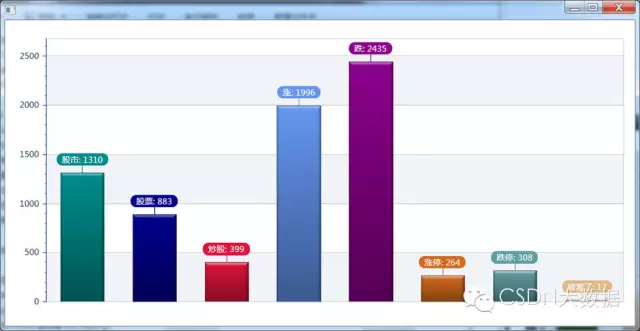
6、下面系列图是根据一些“关键字”在说说中出现的频率统计出来的,相当有意思。
6.1 图说股市
在知乎“能利用爬虫技术做到哪些很酷很有趣很有用的事情?”有一个google实习的哥们@Emily L爬了400亿条tweet也做了很多有趣的分,其中提到一篇关于利用twitter上人的心情来预测股市的论文(http://battleofthequants.net/wp-content/uploads/2013/03/2010-10-15_JOCS_Twitter_Mood.pdf)很有意思。另附我在该问题下的答案“用爬虫监测她(他)的知乎动态”,仅做技术玩乐,求别再喷我猥琐了。
如果当我们拥有海量的QQ空间最新说说,和sina微博数据。我想,用它们来做一些股市或者其它方面的分析预测是可行的,准确度应该也是非常高的。我接下来可能会考虑去做这件有趣的事情。
将股票中的关键字做海量数据分析,比如会得出当日讨论股票排行榜。进而能得到海量讨论股票的用户,再通过市场的实际反馈找出股票上涨及下跌的正相关因子,再对这些海量用户进行分析计算得出最靠谱股票推荐大神排行榜。对这些用户分级,分优先度及抓取密度来拿数据。用这些数据分析出哪些是靠谱的股票肯定靠谱。
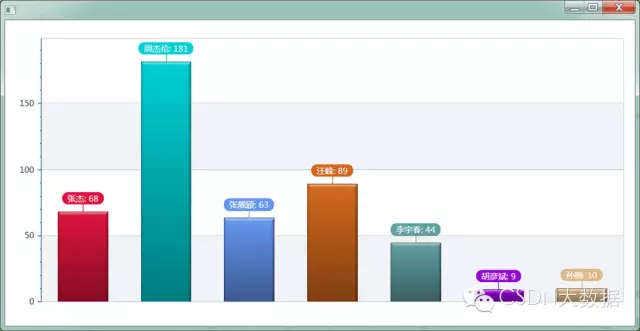
6.2 群众讨论最多的明星排行榜,还是很靠谱的。
另附我抓的明星QQ号吧,纯属娱乐,自辩真假。有些空间确实有很多生活私照。
张杰QQ:419998花千骨的赵丽颖QQ:427794谢娜QQ:500746杨幂QQ:456773范冰冰QQ:88597周杰伦QQ:332661
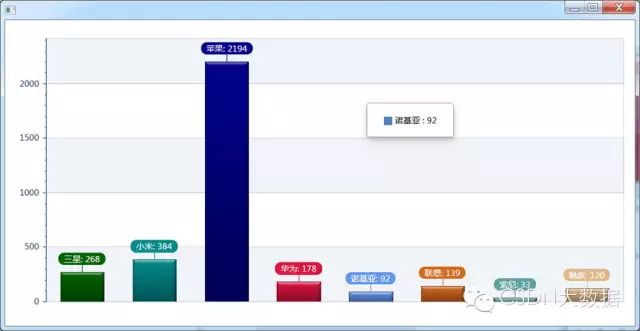
6.3 最为用户喜爱的手机品牌
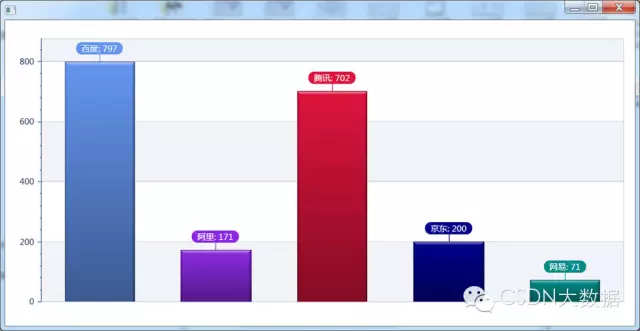
6.4 人们最喜欢谈论的互联网公司,阿里之所以这么低估计是大家都喜欢叫它淘宝或者天猫吧。取这么多名字,自讨苦吃。
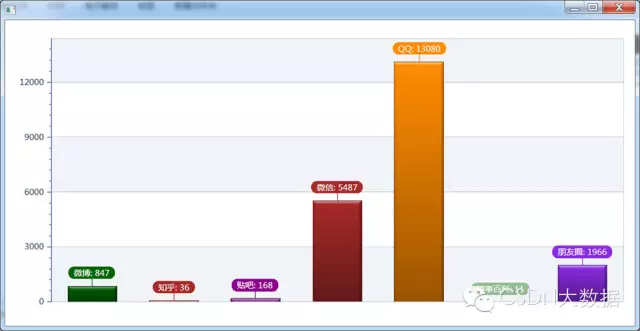
6.5 QQ空间中讨论的最为频繁的社交平台排行榜。
6.6 生活的统计图
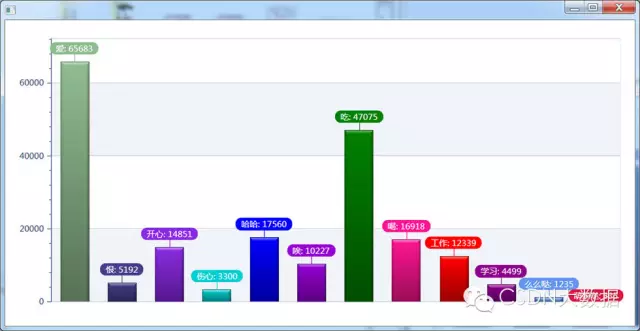
爱>恨; 开心>伤心; 笑声>叹气声; 吃货很多;谁特么说中国不幸福了,这满满的都是正能量数据啊。
好了,其实还可以做很多其它的分析。如果大家有什么有趣的数据分析想知道的,那就给我留言吧。
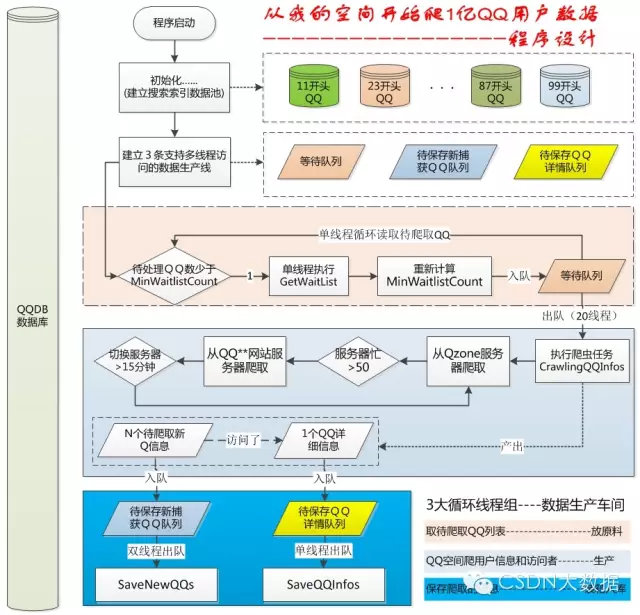
技术不多说了,程序不难,多线程数据库操作却是把我搞苦了。还好,现在程序差不多稳定了。过程也是很有意思的,有空我再写个程序升级过程中的那些趣事吧。我觉得一个美妙的程序一定是高度模拟现实的,就像飞机模仿蜻蜓,雷达模仿蝙蝠一样。这次的程序设计就是模拟的工厂的生产线。附个设计图吧
另外广泛征集大家的聪明点子,能否用这些数据做一个有趣的网站,app。
原文链接:http://www.cnblogs.com/cinser/p/4656386.html


