- A+
有时候我们在做站的时候希望能够找出同行的网站做为参考,或者找出同行做得好的网站,也就是竞争对手的网站。
如果只是简单的人工百度,也能够查找出来一些,但是我们又如何能够确定,哪个网站做得好,哪个网站做得差呢?
我是这样子操作的:
比如我想做一个花卉苗木行业的网站,要找出做得好的竞争对手
第一步:通过百度关键词工具挖出花卉相关词汇
词的数量越多越好,根据行业的大小来定,花卉我挖了16000个。
相关词 搜索量
花卉图片大全 1812
斗南花卉拍卖中心 985
花卉 964
花卉养殖 810
花卉网 478
花卉市场 429
花卉图片 317
花卉大全 225
深圳花卉租摆 216
花卉种子 212
第二步:使用工具把这些词放到百度(英文用谷歌)中搜索
记录每个词第一页的网站,只需要提取主域名即可,然后根据名次赋于分值。这里我用python实现。以下代码供参考,不能够直接使用,因为用了Mongodb做为数据存储。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
import time
import datetime
import re
import traceback
import StringIO
import gzip
import urllib
import urllib2
import cookielib
import pymongo
import hashlib
from bs4 import BeautifulSoup
class collectProductByApi(object):
connection=None
db=None
cat='flower'
t=int(datetime.datetime.now().strftime('%Y%m%d'))
def getDb(self):
while (not self.db) or (not self.db.is_mongos):
self.connection=pymongo.MongoClient("127.0.0.1:1111")
self.db=self.connection.monitor
if (not self.db) or (not self.db.is_mongos):
print "cannot connection to MongoDB"
time.sleep(10)
return self.db
def main(self):
obj=Tool()
while 1:
word=self.getDb().word.find_one({'cat':self.cat,'t':{'$lt':self.t}})
if word:
result=obj.getBaiduSearch(word['w'])
if len(result)==0:
print word['w'].encode('gb2312','ignore'),0
for domain in result:
_analyse_id=self.cat+str(self.t)+domain['d']
_analyse_id=hashlib.md5(_analyse_id.encode('utf8')).hexdigest()
isExsit=self.getDb().analyse.find_one({'_id':_analyse_id})
score=self.getScore(domain['i'])
if not isExsit:
doc={'_id':_analyse_id,'cat':self.cat,'domain':domain['d'],'score':score,'num':1,'t':self.t}
self.getDb().analyse.insert(doc)
else:
self.getDb().analyse.update({'_id':_analyse_id},{'$inc':{'num':1,'score':score}})
print word['w'].encode('gb2312','ignore'),domain['i'],domain['d']
self.getDb().word.update({'_id':word['_id']},{'$set':{'t':self.t}})
else:
self.rank()
print 'End'
return
time.sleep(3)
def getScore(self,index):
x=0
result = {
1: lambda x: 28.56,
2: lambda x: 19.23,
3: lambda x: 10.20,
4: lambda x: 8.14,
5: lambda x: 7.50,
6: lambda x: 5.72,
7: lambda x: 4.01,
8: lambda x: 4.41,
9: lambda x: 5.53,
10: lambda x: 6.70
}[index](x)
return result
def rank(self):
analyse_rows=self.getDb().analyse.find({'cat':self.cat,'rank':None})
for row in analyse_rows:
rank=row['score']/row['num']
row['rank']=rank
self.getDb().analyse.save(row)
print self.cat,row['domain'],rank
print 'End Rank'
class Tool(object):
def getBaiduSearch(self,word):
domains=[]
url= 'http://www.baidu.com/s?wd=%s' % urllib.quote_plus(word.encode('utf8'))
request = urllib2.Request(url)
request.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 5.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101')
request.add_header('Referer',url)
request.add_header('Accept-Language','zh-CN,zh;q=0.8')
request.add_header('Accept-Encoding','gzip,deflate,sdch')
request.add_header('Accept','text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.')
try:
response = urllib2.urlopen(request)
html = response.read()
compressedstream = StringIO.StringIO(html)
gzipper = gzip.GzipFile(fileobj=compressedstream)
data = gzipper.read()
soup = BeautifulSoup(data)
except:
return domains
tables=soup.findAll('table',id=re.compile(r'^\d{1,2}
for table in tables:
index=table["id"]
index=int(index)
span=table.find('span',{'class':'g'})
if span:
site=span.text
site=re.search(r'([a-zA-Z0-9\.\-]+)',site)
domain=site.groups(1)[0]
domains.append({'d':domain,'w':word,'i':index})
return domains
if __name__ == '__main__':
obj=collectProductByApi()
print obj.main()
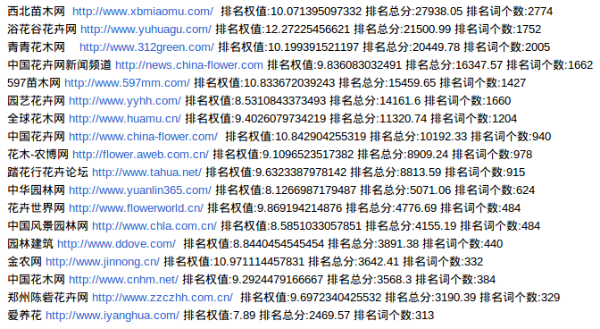
出来的结果

说一下这些数值是怎么来的:
排名词个数代表在16000个词中,这个域名有多少个词在首页有排名。
排名总分就是这些词的排名得分总和,一个词排在第一页第一名,我就就给它加10分。
排名权值就是 总分 除于 词个数
到这里根据总分排一下序,然后去除一下百度之类的平台,人工筛选下,也就能大致确定出行业的主要竞争对手了。
这里的权值是一个很有意义的数据,长期跟踪一个网站的排名权值,可以知道网站有没有被降权之类的。
最后的结果:
附分值表:
google baidu
Rank1: 34.35 28.56
Rank2: 16.96 19.23
Rank3: 11.42 10.20
Rank4: 7.73 8.14
Rank5: 6.19 7.50
Rank6: 5.05 5.72
Rank7: 4.02 4.01
Rank8: 3.47 4.41
Rank9: 2.85 5.53
Rank10: 2.71 6.70
欢迎拍砖。
原文地址:http://www.SEOqx.com/post/91



