- A+
很多人很关心google Caffeine的更新,有些猜测说是为了应对bing的突起而做的改动。
前面讲了很多理论,那这次我们来实践一下,从搜索引擎的角度,来判断一下google Caffeine到底更新了什么。
先看google官方的解释: http://googlewebmastercentral.blogspot.com/2009/08/help-test-some-next-generation.html (需要翻墙)
我觉得,这次改动主要是重写了搜索引擎的底层架构,涉及到爬虫、索引库、排序规则等等很多方面。提升的方向主要是google一直以来追求的速度,而速度的提高会进一步带来准确性和全面性的提升。
Google是一个对速度的追求达到了变态的地步的公司。他们的价值观之一就是“速度为王”。举好几个例子:你可以在google首页看到,所有的代码被压缩成几行,因为这样能提高加载速度,甚至在代码变量的命名上,都是坚持能用1个字母的就不用2个字母的原则;google非常多的产品大量应用AJAX技术,就是为了在速度上更快一点;在google的历史上,曾经想把搜索结果首页的默认条数从10条增多到30条,用户也乐意接受这个改动,但是测试下来,发现这样会拖慢0.5秒的速度就放弃了。
追求速度不光是为了用户打开页面快而考虑的。我相信google在98年就开始意识到这样一个瓶颈问题:摩尔定律描述了每隔数年计算机的硬件水平就翻倍。而互联网上的信息,也是这样一个规律。有人甚至说是每隔9个月互联网上的信息量就翻倍。搜索引擎要保证一个基本的信息查全率,就需要能跟上这种信息暴增的速度。
现在搜素引擎的索引量和互联网上的信息量是这样的一种关系:

互联网和搜索引擎
理论上来说,有越来越多的信息是搜索引擎找不到了的。如:现在百度在收录速度上落后于谷歌,所以谷歌上能找到比百度更多更新的结果。
有这样一个现状在前面摆着,我想搜索引擎想不在意速度都难。google其实从一开始就知道如去做的。首先是有条不紊得增加数据中心的服务器数量,现在google所有数据中心的服务器加起来应该超过一百万台了,目前还在不断的修建数据中心。二是提升这些数据中心的效率。效率的提升有硬件上的也有软件上的。硬件上的就如:自己制造服务器,然后想办法提高每台服务器的速度和稳定性。所以google在服务器硬件上有很多自己的专利;软件效率上的升级也是一直都有的,但是近年来主要的精力应该是放在算法的调整上。我相信这么多年下来,google已经积累了很多底层架构上需要改进的地方,代号“咖啡因”的升级就由此应运而生了。所以不管有没有bing的发布,google都会做这样一个升级。
“咖啡因”的首要的改变会是改进爬虫的效率和提高索引库的速度。从表现上来说,“咖啡因”的第一个表现就是整个搜索引擎的索引量增加了。如果输入单词搜索,每个词语的索引量都增加了很多。搜索的速度也增加了,这是索引库也升级了的缘故。
还有一个我自创的方法,可以来看搜索引擎的整体索引量的。那就是在google.com输入“*a”去搜索。这个搜索的意思是把只要一个网页上有字母a或网页上某个单词里含有字母a的网页都找出来。当然一个网页在99.999%的情况下都有字母a的,所以这个符号的索引量约等于整个搜索引擎的索引量。
“咖啡因”刚发布的时候,用这个符号去搜索,发现 http://www2.sandbox.google.com/ 和 google.com 的索引量差距有80多亿左右。 而现在你去搜索,发现都是一样的数量,大概有254亿。
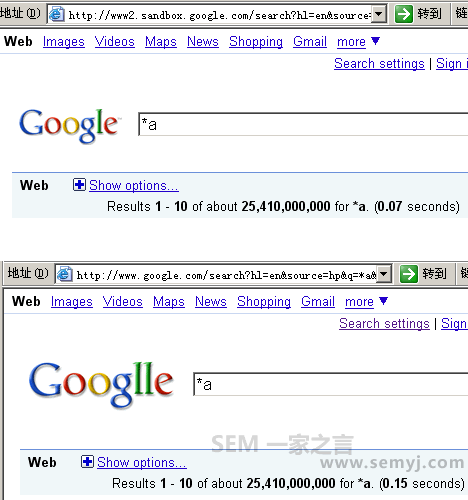
索引量对比
所以现在有一个结论是可以确定的:“咖啡因”抓取的那些页面,现在已经列入到google.com的索引库里了。
只要排序规则不变,有更多的网页参与排名,这对谁都好的,所以google马上就应用了。
索引量增加后,还有另一个最直观的感受应该是:搜索一些长尾词,会看到很多以前不在首页的网页冒了出来。
“搜索引擎的速度跟不上互联网信息的增长速度”这听起来很让人觉得沮丧。不过其实搜索引擎并不一定要追求把互联网上所有的信息都抓取下来的。只要把有价值的信息都能抓取下来即可。那么如何判断一个信息是有价值的呢?这也要依靠数据中心的速度。
现在搜索引擎上的主要问题,不是信息太少了,而是原创的、用户需要的信息太少了。想一想我们自己在搜索引擎上找信息,哪一次不是找遍大量的网页后才找到想要的信息的呢? 要让这些信息很容易被用户找到,基础就是数据中心的效率要很高。如:判断原创性的算法中,爬虫的效率和数据计算的速度提高了,判断原创性就更准确了。还有排序规则里很重要的链接因素,现在的google之所以能比其他搜索引擎更能给用户想要的搜索结果,来自于它3天就可以更新一次数百亿网页的速度,能计算这些网页彼此之间的关系。现在效率提高了,如果1天就可以update完一次,那计算出来的排序就更符合用户的需求了。
这次“咖啡因”的升级应用起来以后,那些依靠采集的垃圾网站会越来越没什么流量。搜索引擎已经索引了40%以上重复的垃圾信息了,而还有那么多有价值的信息等着去索引,如果你是搜索引擎,也会把原创性高的网页的重要性越排越高的。有时效性的网页也是。当然依靠人为制造大量外部链接在做排名的效果也会大打折扣。
不过我觉得,google还是会用更多的时间来测试这次改动。虽然本质上这次升级就是强化以前的一些理念。但是在一个这么大的系统里,这么一次脱胎换骨的改动会产生什么样的影响也还是无法预料的。
可以看到,爬虫、索引库、排序规则,无一不需要数据中心的速度更快。所以我在《分词与索引库》中说:google的数据中心,才是它的核心竞争力之一。google 也把速度快归结为自己成功的原因。
google一直以来都在拼命拉大和竞争对手的距离,已经形成了牢不可破的竞争壁垒。bing这个搜索引擎非常清楚这点,所以只有剑走偏锋,做一些google目前无法部署的事情。但是以后google“咖啡因”完善并上线后,一定又可以为google拿下几个百分点的市场份额。


