- A+
这纯粹是一条个人喜好,我经常拿HTTrack模拟搜索引擎爬虫用。
HTTrack是一个网站镜像工具,本来是用来抓取网站做离线浏览用的。但是我发现它的爬虫特性和搜索引擎爬虫非常的像,逐渐应用到了自己的SEO工作中。其实这两种看似不同的爬虫做的都是同样的工作,就是复制网站并存储下来(搜索引擎的网页快照就是被存储下来的内容)。以下是这个软件的界面:
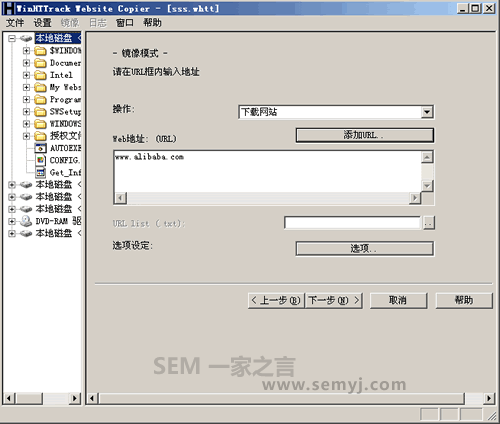
HTTrack界面
软件的官方网站是:http://www.httrack.com/ 软件安装后可以换成中文界面。
一般用它来检测网站的坏链接和测试搜索引擎对这个网站可能面临的抓取问题。另外用它也可以探知一些SEO做法的由来。
软件的使用方法非常简单,在“Web地址”里填上URL就可以了。然后点“选项”,
先看“扫描规则”
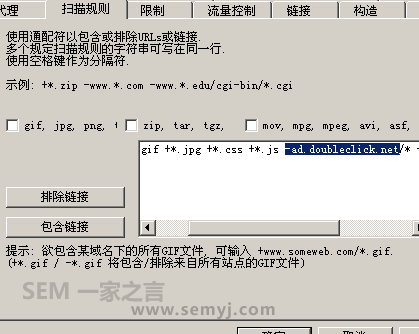
扫描规则
这样的扫描规则搜索引擎也一定会有的,比如不收录.exe文件,zip文件等等。然后不收录一些特定的跟踪链接, 如 ad.doubleclick.net 。你需要把一些搜索引擎爬虫不收录的特征加进去。
然后在“搜寻”里面,很多的特征都是现在搜索引擎爬虫的特征:
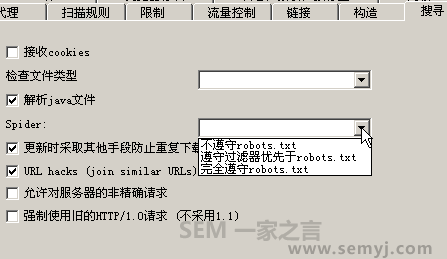
搜寻
搜索引擎不会接受cookie,所以取消“接收cookie”。
至于“解析java文件”,google 爬虫也会去解析java文件的。这是一个像HTTrack这样的通用爬虫都可以做到的事情。可能很多人还不知道,google会去试图解析javascript代码。如果你的页面上放很多javascript代码,就会使爬虫的停留时间增加,进而影响爬虫效率。这也可以算是为什么要把javascript代码外调的另一个原因。
还有,有些javascript代码里面的URL,google爬虫是可以收录的,原因不明。这样做可能是因为有些内容很好的网站,很多链接就是喜欢用javascript来做的缘故吧。但是不代表你的链接可以用javascript来做。
HTTrack也同样能识别并遵守robots.txt文件。
至于url hacks ,就是让那种带 www和不带www的网址,如www.***.com和 ***.com。以及有斜杠和无斜杠的网址,如http://www.***.com 和 www.***.com 能统一。
这种网站上URL不统一的状况爬虫程序其实能很简单的处理好。至于google为什么要网站所有者在webmaster tool 后台指定一下“首选域”,是因为有些网站 www.***.com 和***.com 指向不同的内容。所以google不能那么武断的就认为www.***.com 和***.com是同一个网站。
至于“流量控制”和“限制”,
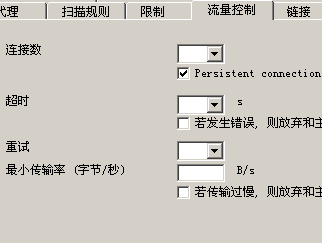
流量控制
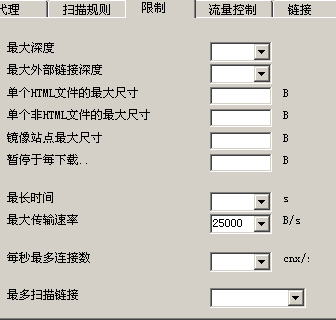
限制
里面可以设置“连接数”和“深度”什么的。我相信google也有这些设置,不然,google的《网站质量指南》里不会这么写“如果站点地图上的链接超过 100 个,则需要将站点地图拆分为多个网页。”
至于深度,有报告说,google抓取的最大深度是12。超时时间可以设为10秒。
还有其他“浏览器标识”和“预存区”也和搜索引擎爬虫一样的。
其他设置
下面用它来抓取一个网站,看看会有什么样的情况。
首先爬虫会去网站根目录下访问 robots.txt文件,如果碰到该网站的二级域名,还会去二级域名下访问robots.txt文件。这个和搜索引擎是一样的。
在抓取的时候,是多线程的,你可以实时的看到哪些URL正在被抓取以及速度怎么样。
很多人用它抓取完一个网站后会惊讶的发现有很多没什么SEO价值的页面在被抓取。而这些“垃圾链接”竟然还是最先被抓取到的。可惜这个爬虫不支持nofollow属性,不然更加能模拟google爬虫。你还会用它发现很多死链接和超时的页面。
要是经常使用,你还会发现这个软件的一个规律,就是在抓取那些动态URL的时候,经常会产生重复抓取的现象,抓取URL类似www.***.com/index.asp?=12345 这样页面会陷入到死循环当中。这个和早期的google爬虫又是一样的。由此判断,这应该是爬虫天生的一个弱点,可能它没办法实时的比较多个页面的内容,如果加上网页程序在处理URL ID的上遇到什么问题,就会重复抓取。也由此得出为什么要有URL静态化了。 URL的静态化与其叫静态化不如叫唯一化,其实只要给网页内容一个唯一的、结构不容易陷入死循环的URL即可,这就是静态化的本质。
google最新的声明不要静态化,是不希望爬虫从一种重复抓取陷入到另一种重复抓取才这样说的。其实google举例的那几种不好的静态化一般是不会发生的。只要你明白那些URL中的参数代表什么,还有不要把很多个参数直接rewrite到静态化的URL里即可。
用这个软件,能让你直观的感受一个爬虫是怎么工作的。对于让一个新手正确认识爬虫有帮助。
这个软件的功能也差不多就这么多,要逼真的模拟搜索引擎爬虫,就要用《google网站质量指南》里提到的Lynx。但是Lynx是一个页面一个页面检查的。以后会写一篇应用Lynx的文章。
更好的模拟google爬虫就要用GSA了。不应该说是模拟,而应该说它就是google爬虫。
用HTTrack、Lynx和GSA,再配合服务器LOG日志里面的爬虫分析,会让你对爬虫的了解到达一个更高的水平。分析爬虫会让你得益很多的。很多都以后再讲。


