- A+
SEO大部分工作都是围绕“关键词、网站内容、链接结构”这3个点展开的,每个点都需要依托数据分析技巧。而关键词作为第一步,其目标是了解用户搜索需求及不同用户在不同场景下产生的搜索行为,并对应网站内容,找到目前忽略的搜索流量。对网站内容和链接的建设方向起到直接的指导作用。
纵观各种SEO论坛,提到关键词分析都常出现以下几个问题:
1、关键词词如何归类
2、相似的词如何处理
3、这些词怎么用
面对条目繁多、类型复杂的原始词表,纯人工处理显然不现实,纯程序处理显然不准确。所以需要使用很多个小技巧,用程序处理原始词表,输出候选分组和指定的参考数据,在人工来甄选的方式,高效快速且保证质量的解决上述问题,大体过程如下:
1、获取原始词表,我这里的用的是百度推广API,也可以用百度凤巢、搜索引擎下拉框及相关搜索、竞品数据等,方法及现成的工具很多,就不在多说了,数据如下图:
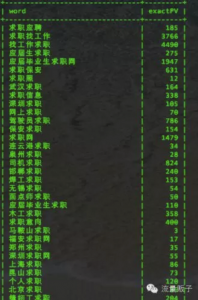
2、对原始词表进行处理。
大多数用户都会使用共性的搜索组合,约占60%~70%的比例,每个组合都包含“词缀”和“变量”。
比如:“北京在哪租房便宜”,这里的“北京”就是一个地域变量,“北京”本身可以替换任何城市、区县、街道等地域有关的名词,“在哪租房便宜”则是词缀,词缀是写死在模板上的,而不是像变量一样动态调出来的。
另外一般搜索量高的词,都会对应多个意思相同的词,如“北京哪里租房便宜”、“北京去哪租房便宜”等。
拿到原始词表,接下来要做的,是对原始词表进行初步的分组,为接下来的人工甄选提供可靠的数据支持。需要什么数据需要结合实际来定,下面的例子是按我个人的习惯来的。
具体操作为:已词根为分界点,提取原始词表中每个词,词根前面和后面的部分,即这个词的前缀和后缀,之后计算每个词缀的在所有词中的出现次数及对应的总搜索量。
这是处理后的原始词表:
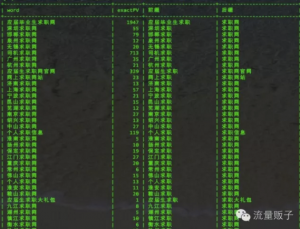
这是计算出来的词缀数据:

3、人工甄别,提取变量。
词缀已经找出来,还差对应的变量。由于变量的复杂性、多样性,还是需要人工快速的过一眼。
由于上一步已经把词缀数据都计算好了,将词缀按总搜索量降序,找出前缀、后缀搜索量前200的词缀,然后快速过一眼包含这个词缀的关键词都有哪些变量,都记录下来。
记录的格式可以自由发挥,结合实际情况,记录自己分析所需要的数据。
我的记录方式如下图,左边蓝框是同类词缀,即“搜索需求相同,但搜索行为不同”的相似词。右边蓝框的是对应的高频搜索组合,包含不同的组合模式或不同变量。
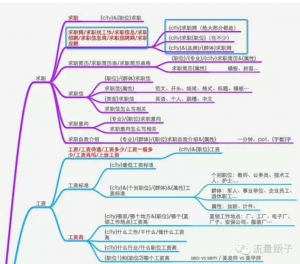
4、数据使用。
这个没有固定的方法,看网站情况实际而论。但比较统一的方式是,同类词缀都放到一个页面内、高搜索量词缀放title,低搜索量词缀合理嵌入页面,比如上图蓝框部分:

总共有7个词缀,先查找下每个词缀对应的总搜索量,把搜索量靠前的词缀优先放到title上,剩下搜索量低的合理的嵌入页面中,比如在页面底部加上该页面的文本说明,如‘访问过该页面的用户还搜了:“{city}求职招聘网、{city}求职应聘、{city}求职信息网”’
因为搜索量低的词缀如果变量很多的话,潜在的长尾流量加一块也不少,因竞争度小,互联网中包含这些长尾词的网页不多,如果网站中有一个网页或多个网页中能够完整的出现这些长尾词,那么这些词展现的几率会大很多。
这里有个抢占搜索引擎优质索引库的意识。百度是分三层索引,优质库、普通库、低质库,优质库的网页数量占总索引库20%,却能够满足60%以上的检索需求。在优质库的网页才会有展现的机会,所以同一类搜索词,最好合理嵌入A、B、C等多类页面,万一A挂了一部分页面没进入优质库,没关系,没准B、C能补进去呢。
也有很多人会碰到这种情况,“求职网、求职找工作”是以“求职”为词根,搜索量高,得放到title上,那已“招聘”为词根的“招聘网、招聘找工作”搜索量也很高,一个title没法放那么多搜索量高的词,怎么办?
建议不同词根但需求相同且竞争难度较大的词,用不同的页面分别承载对应的流量。比如“求职”和“招聘”,页面对应的内容都是招聘信息,所以如果“求职”已经有页面的话,建议用同样的数据,与求职页面不同的调用方式、不同的模板做一套新页面来捕获招聘的流量。
还有一个词共现的问题,用试过几次,找“马云”“阿里云”“万网”这种语义关系上挺好用的,对于关键词分析,如新闻咨询那种搜索词关联性不强的站,可以人工设定几个种子词,导出对应的文章,通过分析种子词上下文提取与种子词关联性强的TAG词。网上有现成的工具包:word2vec,可以很方便的实现上述需求。但对于常规网站的关键词分析,个人感觉作用不大。
另外也别考虑有什么程序能够一步到位,程序只负责处理,最终决策还得靠人。



2015-12-31 下午12:07
谢了.学习中,先顶
2015-12-29 上午9:39
文章不是转过吗?怎么又转一遍
来自外部的引用: 1