- A+
今天看到@Brooks大神分享了一个百度推广后台关键词批量挖掘并导出的Python程序,分享出来给大家。
下面给大家简单介绍一下怎么用。
首先你需要将工具下载到你电脑上(点击下载百度凤巢推广关键词批量挖掘导出工具),解压开来,应该能看到如下图的文件:

顺序给大家介绍一下各文件的作用:
resultkeys.txt是关键词导出的结果
failed.txt是查询失败的关键词
cookies.txt是存放你自己登录账号后的 cookies的,后面会讲怎么获取
checkwords.txt是你需要拓展的关键词词根,或者叫母词吧!
bdfengchao.py是主程序,Python写的。
下面就是bdfengchao.py的源代码:
- # -*- coding: utf-8 -*-
- """
- verseion: beta2.1
- 说明:
- 百度凤巢挖词脚本 (代码符合PEP8标注)
- 利用百度凤巢关键词规划师工具进行关键词挖掘
- 用到第三方模块:requests
- 详见:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
- 作者:Brooks,QQ:76231607
- 请勿用于任何商业用户,版权最终归作者所有
- """
- import requests
- import json
- import time
- def get_result_data(key, uconfig, cookie, retry=3):
- """获取关键词查询结果数据
- :param key: 要查询的关键词
- :param uconfig: 用户配置信息
- :param cookie: cookie登录信息
- :param retry: 链接过程失败重试次数
- :return: 返回json类型数据以及错误信息
- """
- headers = {
- 'Accept': '*/*',
- 'Accept-Encoding': 'gzip, deflate',
- 'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6',
- 'Connection': 'keep-alive',
- 'Content-Type': 'application/x-www-form-urlencoded',
- 'Cookie': cookie,
- 'Host': 'fengchao.baidu.com',
- 'Origin': 'http://fengchao.baidu.com',
- 'Referer': 'http://fengchao.baidu.com/nirvana/main.html?userid=%s' % uconfig['userid'],
- 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 '
- '(KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
- }
- query = 'http://fengchao.baidu.com/nirvana/request.ajax?'\
- 'path=jupiter/GET/kr/word&reqid=%s' % uconfig['reqid']
- params = {
- "logid": -1,
- "query": key,
- "querySessions": [key],
- "querytype": 1,
- "regions": "0",
- "device": 0,
- "rgfilter": 1,
- "entry": "kr_wordlist_addwords",
- "planid": "0",
- "unitid": "0",
- "needAutounit": False,
- "filterAccountWord": True,
- "attrShowReasonTag": [],
- "attrBusinessPointTag": [],
- "attrWordContainTag": [],
- "showWordContain": "",
- "showWordNotContain": "",
- "pageNo": 1, # 由于pageSize已经是1000,所以不需要再进行分页查询
- "pageSize": 1000,
- "orderBy": "",
- "order": "",
- "forceReload": True
- }
- form_data = {
- 'params': json.dumps(params),
- 'path': 'jupiter/GET/kr/word',
- 'userid': uconfig['userid'],
- 'token': uconfig['token'],
- 'eventId': uconfig['eventId'],
- 'reqid': uconfig['reqid']
- }
- try:
- resp = requests.post(query, headers=headers, data=form_data, timeout=10)
- except requests.exceptions.RequestException:
- resultitem = {}
- err = "请求了那么多次,百度还是没给返回正确的信息!"
- if retry > 0:
- return get_result_data(key, uconfig, cookie, retry - 1)
- else:
- resp.encoding = 'utf-8'
- try:
- resultitem = resp.json()
- except ValueError:
- resultitem = {}
- err = "获取不到json数据,可能是被封了吧,谁知道呢?"
- else:
- err = None
- return resultitem, err
- def parse_data(datas):
- """用于解析获取回来的json数据
- :param datas: json格式的数据
- :return: 返回关键词列表以及错误信息
- """
- try:
- resultitem = datas['data']['group'][0]['resultitem']
- except (KeyError, ValueError, TypeError):
- kws = []
- err = '获取不到关键词数据'
- else:
- kws = ['{}\t{}'.format(item['word'].encode('utf-8'), item['pv']) for item in resultitem]
- err = None
- return kws, err
- if __name__ == '__main__':
- sfile = open('resultkeys.txt', 'w') # 结果保存文件
- faileds = open('faileds.txt', 'w') # 查询失败保存文件
- checkwords = [word.strip() for word in open('checkwords.txt')] # 要查询的关键词列表
- cookies = open('cookie.txt').read().strip() # cookie文件, 里面只放一条可用的cookie即可
- # 用户配置信息,请自行登录百度凤巢后台通过抓包获取 (以下只是虚拟数据不能直接使用)
- config = {
- 'userid': 6112345,
- 'token': 'e3223414e798481dd281123459971fed37abba41c64dcdb224e7c5000000000b0a0fa26f1f0a086f2bb59d',
- 'eventId': '12344c46-12a4-12a4-1209-123474436233',
- 'reqid': '12344c46-12a4-12a4-3a59-123474436233'
- }
- for word in checkwords:
- print '正在查询:', word
- print '-' * 50
- dataresult, error = get_result_data(word, config, cookies)
- if error:
- print word, error
- faileds.write('%s\n' % word)
- faileds.flush()
- continue
- keywordlist, error = parse_data(dataresult)
- if error:
- print word, error
- faileds.write('%s\n' % word)
- faileds.flush()
- continue
- for kw in keywordlist:
- sfile.write("%s\n" % kw)
- sfile.flush()
- print kw
- print '=' * 50
- time.sleep(2) # 每个词的查询间隔时间为2秒,如果不怕被封,可以直接去掉
- sfile.close()
- faileds.close()
- print "所有关键词查询完毕"
效果如下图所示:

下面来给大家说说关键部分,如何获取工具中必备的cookie信息,以及其他几个值
第一步,最好使用Google Chrome来登录自己的百度推广账号
第二步,打开关键词规划师,URL大概是http://fengchao.baidu.com/nirvana/main.html?userid=1234567#/overview/index~openTools=krStation
第三步,按下F12,打开浏览器的开发者工具,切换到Network选项卡,然后搜索一个词,例如“SEO”,然后。。。。不知道咋说,看图吧!把Cookie:后面的值复制下来,存到cookie.txt里
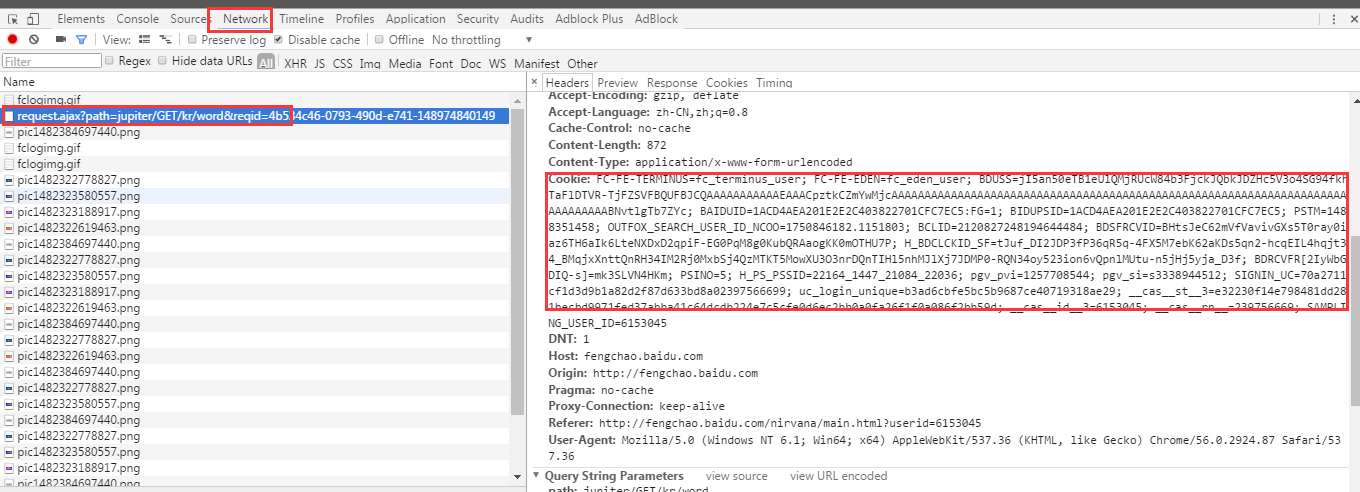
然后将下面红框中的信息,相应填到程序源代码里替换原来的。
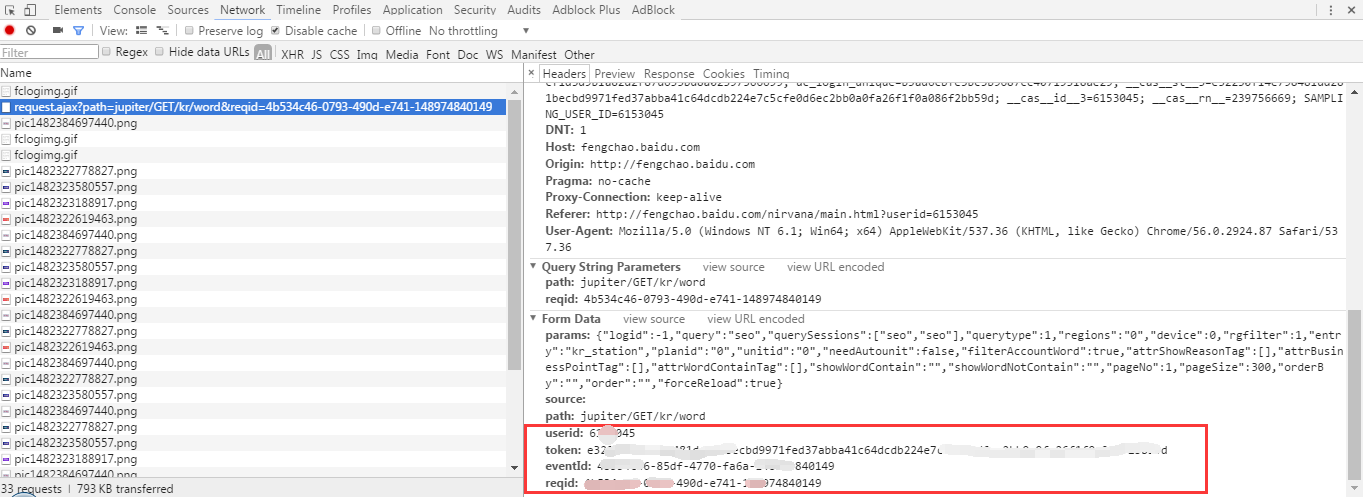
然后,就直接运行bdfengchao.py吧,结果就出来了。。。。。。
写教程好累,这么简单的操作,写出来这么麻烦。。。。哎,自己领悟吧。
如果有帮助,下面留个言吧。




2017-06-19 下午5:22
最近不好用了,基本上都被redirect到百度cas.baidu.com这个网址
2017-04-07 下午3:26
百度推广有个API可以直接获取词啊,而且是批量获取,一次可以提交100个种子词
API更方便点
2017-03-31 下午10:48
现在是不是不能用了???
2017-03-28 下午7:55
看见是17年更新的,相信还能用,就按教程做了
第一次使用python,遇到个小问题,给本地环境安装requests安装包,就可以正常使用了,感谢@方法 @@Brooks
2017-03-28 下午11:08
@阿锋 应该说是的2017年3月更新的 :)