- A+
shell批量、多层挖掘百度相关搜索关键词
用法:
将下面的源代码整个复制,另存为xg.sh,在cygwin里运行time bash -x xg.sh。

注意
xiangguan.sh,kws.txt在同一个文件夹里。kws.txt是母词表,一行一个,一定要用notepad++把格式转换为UTF-8无BOM(菜单-格式-转为UTF-8无BOM编码格式)

shell源代码
#/bin/bash
#批量查所给定母词的相关搜索词
#by 方法@seofangfa.com
#cat kws.txt|while read line;do curl -s "http://www.baidu.com/s?wd=$line&tn=baidurs2top"|sed 's/,/\n/g'>>related.txt;done
#重点要说三遍
#kws.txt是母词表,一行一个,一定要用notepad++把格式转换为UTF-8无BOM(菜单-格式-转为UTF-8无BOM编码格式)
#kws.txt是母词表,一行一个,一定要用notepad++把格式转换为UTF-8无BOM(菜单-格式-转为UTF-8无BOM编码格式)
#kws.txt是母词表,一行一个,一定要用notepad++把格式转换为UTF-8无BOM(菜单-格式-转为UTF-8无BOM编码格式)
#xg.txt是最终输出的结果文件
xiangguan()#定义一个函数
{sum=`expr $RANDOM % 11`
echo "随机暂停$sum秒...."
sleep $sum
a=0
sort -u kws.txt>1.txt
for i in `cat 1.txt`;do
let a+=1
echo $a,$i
curl -s "http://www.baidu.com/s?wd=$i&tn=baidurs2top"|sed 's/,/\n/g'>>kws.txt
echo "" >>kws.txt
done
}
for a in `seq 1 4`;do #默认是挖掘4层,如果需要挖掘更多层,把4改为其他数字就行了。
echo "开始挖第$a层...."
sleep 2
xiangguan
done
sort kws.txt|uniq -c|sort -nr >xg.txt
rm -rf 1.txt
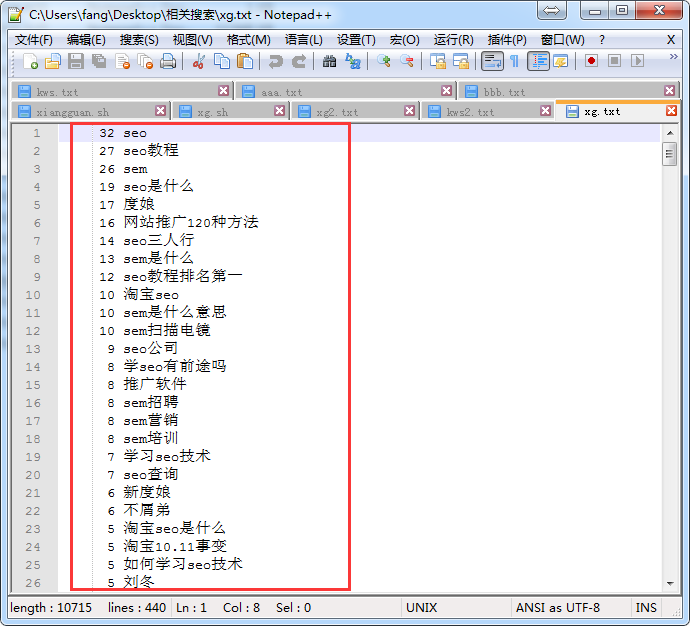
效果
选了两个母词,SEO和sem,跑3层下来效果如下图,喜欢折腾shell的,可以亲自试一下。
源代码打包下载
有朋友反应将代码粘贴回去,老是有报错,我就把xg.sh这个文件打包发一下,有需要的点此下载。




2017-11-14 下午7:51
tn baidurs2top已失效,有替代?
2016-04-07 下午10:39
sort: 字符串比较出现错误: Invalid or incomplete multibyte or wide character
sort: 请设置LC_ALL=’C’ 以避免出现问题。
sort: 要比较的字符串为”SEOr” 和”SEO305340ѵ”。
提示这个是因为什么呢
2015-11-09 下午11:37
很明显是你没有安装curl,安装教程博客有视频教程
2015-11-09 下午6:42
弄了一天还是提示:xg.sh:行24: curl: 未找到命令
2015-09-23 下午6:01
赞一个,已收藏,有空研究研究
2015-09-23 下午5:58
赞一个,已收藏,有空研究眼睛
2015-09-19 下午6:53
高端seo!赞一个。留个脚印…
2015-09-08 上午12:25
这个不错哟