- A+
大型SQL文件导入mysql方案
一. 场景
现有俩个体积较大的单表sql文件,一个为8G,一个为4G,要在一天内完整导入到阿里云的mysql中,需要同时蛮子时间和空间这俩种要求。
二. 思路
搜索了网上一堆的方案,总结了如下几个:
方案一:利用navicat远程导入
方案二:在阿里云ECS安装一个mysql-client,用source方案导入
方案三:购买阿里云DBMS高级版服务,可以导入1G以内ZIP压缩包
三. 尝试
折腾了许久的尝试,终于总结了一下的经验:
3.1 尝试navicat远程导入
操作简单,但是缺点很明显:导入效率低,严重占用本地的IO,影响机器的正常工作,所以立马放弃。
3.2 尝试source方案
3.2.1 实现步骤
STEP1 在测试环境的ECS上安装一个mysql-client
STEP2 修改mysql中的max_allowed_packet参数为10G大小,net_buffer_length参数也根据需求适度调大。
STEP3 因为是俩个表,写俩个脚本太麻烦了,可以利用一个sql脚本聚合实现,所以all.sql 的内容可以如下
source /mydata/sql/a.sql;
source /mydata/sql/b.sql;
STEP4 为避免ssh连接掉线而导致执行关闭,需要写一个shell脚本,通过nohup后台执行。
myshell.sh脚本如下
mysql -h host -uxxx -pxxx --database=user_database</mydata/sql/all.sql
STEP5 后台执行指令
nohup ./myshell.sh &
3.2.2 结果
测试速度相对快多了,但是由于第二天就需要,所以俩个表接近4000w行的数据绝对不能完成任务,所以方案取消。但是不是否定该方案,其他场景肯定满足。
3.3 尝试DMBS
由于我们数据库是阿里云的RDS,所以我们购买了对应的DBMS服务升级版,可以支持文件上传导入(包含1G内的ZIP)
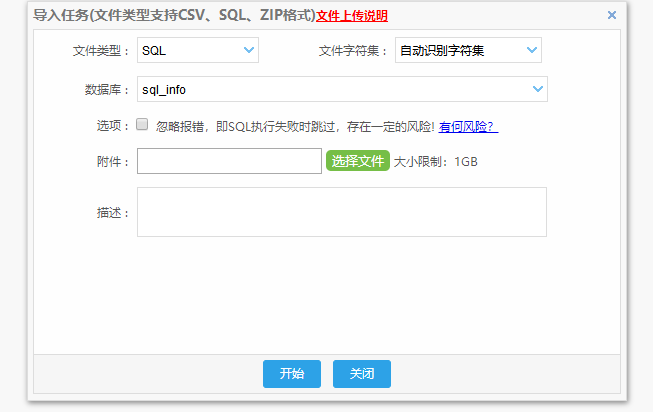
DBMS功能
3.3.1 压缩文件
压缩单表SQL文件为单独zip文件,压缩下来一个为0.9G,一个为1.2G
3.3.2 拆分文件
第一个sql文件上传后执行很顺利,但是第二个1.2G的zip包需要进行拆分
3.3.3 拆分方案
1.拆分zip压缩包
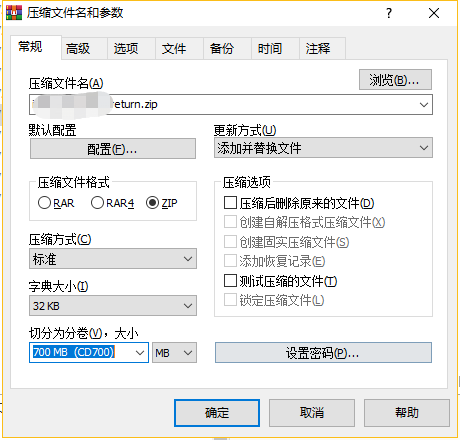
压缩包拆分
拆分出来的文件,手动改后缀后不满足DBMS的文件规范,失败~
2.高比例压缩文件
利用7z高比例压缩sql为7z后缀,压缩后体积明显小了,只有0.7G的体积,然后通过更改后缀为zip来上传。结果阿里云解析不出这样的格式,失败~
3.使用linux split 命令
split [--help][--version][-<行数>][-b <字节>][-C <字节>][-l <行数>][要切割的文件][输出文件名]
补充说明:
split可将文件切成较小的文件,预设每1000行会切成一个小文件。
-<行数>或-l<行数> 指定每多少行就要切成一个小文件。
-b<字节> 指定每多少字就要切成一个小文件。支持单位:m,k
-C<字节> 与-b参数类似,但切割时尽量维持每行的完整性。
虽然linux可以根据行拆分文件(这也是阿里云工单提供的解决方案),但是这个操作上传上去拆分,在下载下来上传到DBMS,文件体积这么大,来来回回一天过去了,所以放弃~
4.拆分单表sql文件为多份
网上有个SQLDumpSplitter的工具可以拆分表为多份,但是搜索记录中和文章中都是推荐SQLDumpSplitter2的版本,版本太老了,体积较大的sql完全不支持,失败~
但是!我在SQLDumpSplitter2里面看到了软件的官网,发现官网有SQLDumpSplitter3版本,不抱希望的尝试了一下,居然支持大体积文件。成功了!!!
附带下载链接:https://philiplb.de/sqldumpsplitter3/ 太值得推广了。
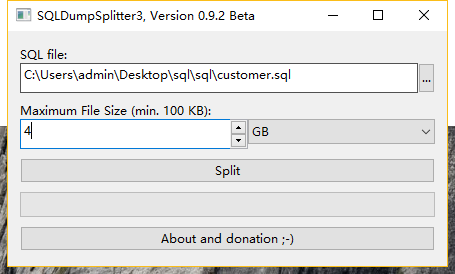
SQLDumpSplitter3
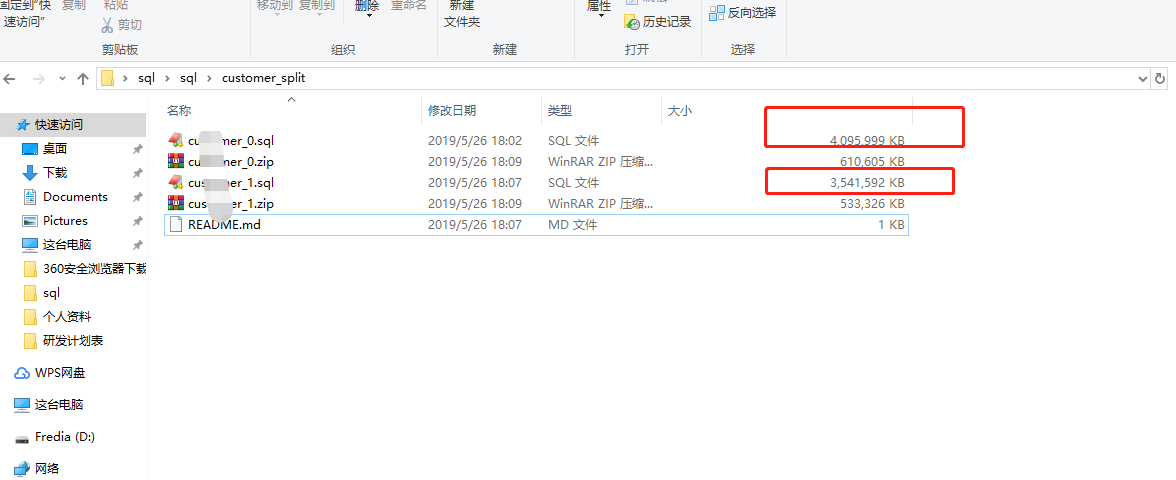
拆分结果
剩下就是按序上传对应文件即可完成,不得不得夸阿里云这方面做得真的好!
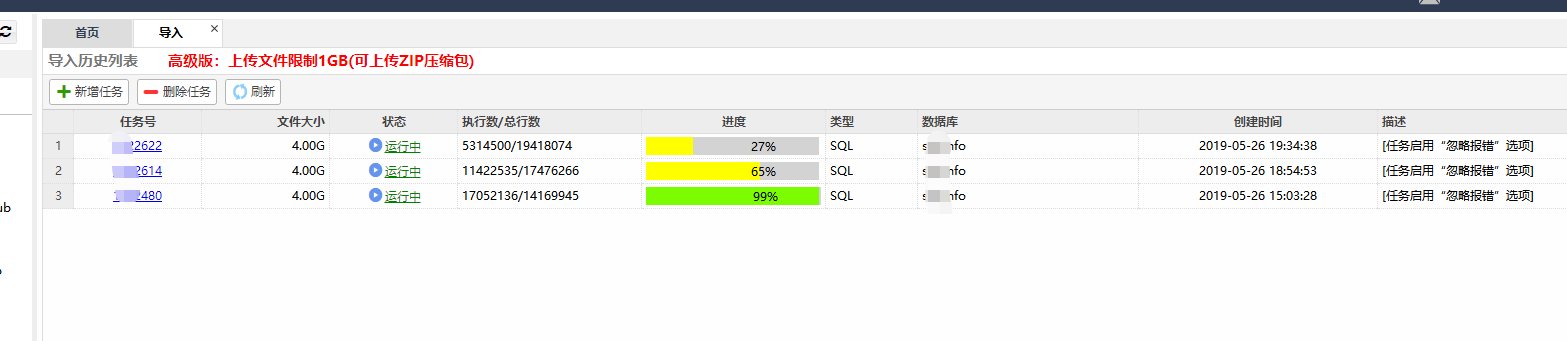
多任务执行
执行效率上面来说,也是可圈可点的:

切片入库的效率
四. 总结
今天针对这个需求,我首先查询了网上的大体方案,然后挑选了几个可执行的方案进行测试。排除了多个方案的情况下,采用了第三方的解决方案来完成这个问题。在阿里云DBMS的支持下,我们又尝试了多种文件的切割方案,最后通过SQLDumpSplitter3+DBMS来实现了,并且效率可观。过程中也发现,常用的client-source方案可以满足自建mysql+效率要求不是极致的场景。
综上,对于大型sql,最好的方案也是先切割(确保顺序性),然后利用一些更高效率的软件执行来实现最终结果,也需要根据时间空间场景灵活选用方案。



