- A+

之前抓一个爬虫代理网站,发现在port上做了点手脚,使用了JS去计算port的方式,比如<script>document.write((2773^seal)+837);</script>。就这样一个改动搞得我费劲心思,用最笨的方法虽然能实现,但太繁琐,代码量太大,有一种操作起重机抓纸牌的感觉。最后想到了Selenium的方式,虽然速度慢了点,但可以轻松获取。
安装
Linux
sudo pip install selenium sudo apt-get install PhantomJS
Windows
- Selenium下载地址:https://pypi.python.org/pypi/selenium#downloads
- PhantomJS下载地址:http://phantomjs.org/download.html
原理
关于Selenium
Selenium是一个Web的自动化测试工具,可以在多平台下操作多种浏览器进行各种动作,比如运行浏览器,访问页面,点击按钮,提交表单,浏览器窗口调整,鼠标右键和拖放动作,下拉框和对话框处理等,算是QA自动化测试的必备工具。我们抓取时选用它,主要是Selenium可以渲染页面,运行页面中的JS,以及其点击按钮,提交表单等操作。但就是因为Selenium会渲染页面,所以相对于requests+BeautifulSoup会慢上一些。
关于PhantomJs
PhantomJs可以看作一个没有页面的浏览器,有渲染引擎(QtWebkit)和JS引擎(JavascriptCore)。PhantomJs有DOM渲染,JS运行,网络访问,网页截图等多个功能。
使用PhantomJS,而不用Chromedriver和firefox,主要是因为PhantomJS的静默方式(后台运行,不打开浏览器)。
抓取示例
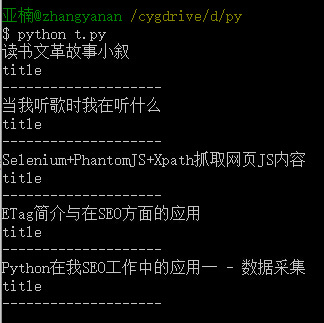
牛刀小试 - 抓取zhidaow.com Title
先拿一个简单的例子试手,之前这样的内容一般用requests+BeautifulSoup或者Scrapy处理。
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe') #浏览器初始化;Win下需要设置phantomjs路径,linux下置空即可
url = 'http://www.zhidaow.com' # 设置访问路径
browser.get(url) # 打开网页
title = browser.find_elements_by_xpath('//h2') # 用xpath获取元素
for t in title: # 遍历输出
print t.text # 输出其中文本
print t.get_attribute('class') # 输出属性值
browser.quit() # 关闭浏览器。当出现异常时记得在任务浏览器中关闭PhantomJS,因为会有多个PhantomJS在运行状态,影响电脑性能
以下是本次测试的运行结果:
抓取爱站流量
爱站在网站的综合查询首页(如http://www.aizhan.com/siteall/tuniu.com/),历史流量部分采用了JS的形式。抓取这部分数据,requests+BeautifulSoup就使不上力了,也正是Selenium+PhantomJS的优势所在。
以下是代码:
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe')
url = 'http://www.aizhan.com/siteall/tuniu.com/'
browser.get(url)
table = browser.find_elements_by_xpath('//*[@id="history1"]/table/tbody/tr[1]') # 用Xpath获取table元素
for t in table:
print t.text
rowser.quit()
运行结果:
2015-09-24 3534 - - - -
其他功能
- browser.page_source # 源代码,可结合BeautifulSoup使用
- browser.current_url # 当前URL
参考资料
- selenium webdriver (python)第三版,来自博客园--虫师(因为收费文档,所以不能分享)
- Headless Selenium Testing With Python and PhantomJS
备注
图片来自500px.com,by Kurt Arrigo。
文章来源:张亚楠博客http://www.zhidaow.com/post/selenium-phantomjs-xpath

2015-12-01 上午11:18
【老大】–帮问:具体怎样实现首页LOGO为H1标签,而内页其它页面的LOGO则变成不是H1标签?谢谢。 请详细指点下。。。。。。。。。