- A+
一直想写一篇用shell采集百度下拉框关键词的教程,个人感觉用shell来采集的话速度和效率都会更高一点。因为前面写过一篇用火车头采集百度下拉框关键词的教程,操作步骤稍微多了些,很多朋友看完了仍然不知道怎么做,然后QQ问我,教程都写得很清楚明了,只要对照着来做,一定会成功的。
-------------------------------2015年5月22日补充-------------------------------
刚看到小五给了一个可以批量采集百度下拉框的百度接口,简单修改下,已经用shell实现了批量采集,代码如下:
采集单个词测试一下:
curl -s "https://sp0.baidu.com/5a1Fazu8AA54nxGko9WTAnF6hhy/su?wd=seo"|iconv -f gbk -t utf-8|awk -F":" '{print $4}'|grep -oP '(?<=").*?(?=")'|sed 's/,//g'
效果如下图所示:

指定一批母词,批量采集代码:
cat kws.txt|while read line;do curl -s "https://sp0.baidu.com/5a1Fazu8AA54nxGko9WTAnF6hhy/su?wd=$line"|iconv -f gbk -t utf-8|awk -F":" '{print $4}'|grep -oP '(?<=").*?(?=")'|sed 's/,//g';done
效果如下图,如果你的母词很多的话,建议在代码后面加一个重定向命令,将结果实时写入到文件中,这样比较好复制一些。给出完整代码吧:
cat kws.txt|while read line;do curl -s "https://sp0.baidu.com/5a1Fazu8AA54nxGko9WTAnF6hhy/su?wd=$line"|iconv -f gbk -t utf-8|awk -F":" '{print $4}'|grep -oP '(?<=").*?(?=")'|sed 's/,//g';done >ok.txt
结果会实时写入ok.txt文件中。

shell批量采集百度下拉框关键词另一个可用的百度API:
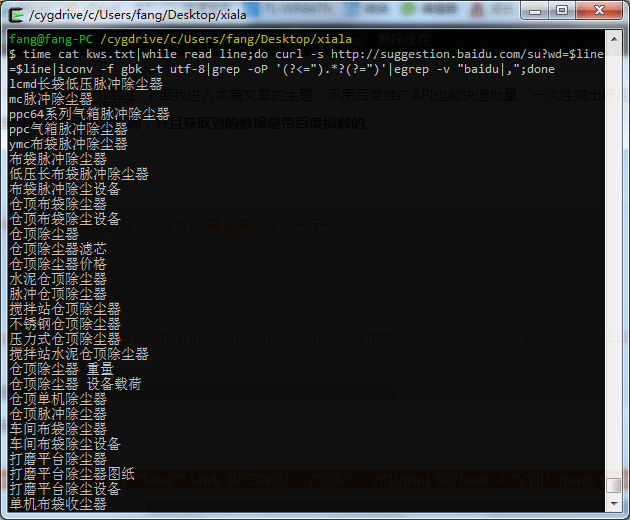
cat kws.txt|while read line;do curl -s http://suggestion.baidu.com/su?wd=$line=$line|iconv -f gbk -t utf-8|grep -oP '(?<=").*?(?=")'|egrep -v "baidu|,";done
效果如下图:
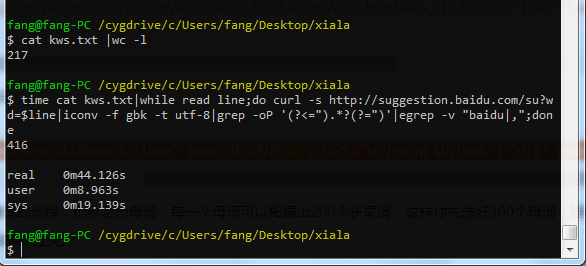
采集效率如下图,217个母词,不到一分钟采集到了416个下拉词,效率如何?



2016-07-20 上午9:41
博主的文章不错!!
2016-03-30 上午11:41
保存的ok.txt里面默认不会换行啊?
2016-07-12 下午5:23
@杨超SEO unix2dos一下
2016-01-10 下午3:44
-bash: sad: 未找到命令
2016-01-08 下午11:01
不好使- -。
2015-09-18 上午1:22
补充一下母词文本的k***s.txt的写法就更好了
2015-07-17 上午12:54
不懂shell,可否进一步傻瓜化呢?
2015-07-03 下午11:18
词出不来啊啊啊啊啊啊
来自外部的引用: 4