- A+
所属分类:shell学习笔记
cygwin下用Python比较两个文本的相似性,使用到了结巴分词以及余弦定理。
关于cygwin的安装以及python的安装,暂且不提,大家可以去看另一篇http://seofangfa.com/shell/shell-extract-404-pages.html
关于结巴分词,大家可以看看这篇文章《cygwin下用Python+jieba给文本分词并提取高频词》
#!/usr/bin/env python
# -*- coding: utf-8 -*
import re
from math import sqrt
#You have to install the python lib
import jieba
def file_reader(filename,filename2):
file_words = {}
ignore_list = [u'的',u'了',u'和',u'呢',u'啊',u'哦',u'恩',u'嗯',u'吧'];
accepted_chars = re.compile(ur"[\\u4E00-\\u9FA5]+")
file_object = open(filename)
try:
all_the_text = file_object.read()
seg_list = jieba.cut(all_the_text, cut_all=True)
#print "/ ".join(seg_list)
for s in seg_list:
if accepted_chars.match(s) and s not in ignore_list:
if s not in file_words.keys():
file_words展开 = [1,0]
else:
file_words展开[0] += 1
finally:
file_object.close()
file_object2 = open(filename2)
try:
all_the_text = file_object2.read()
seg_list = jieba.cut(all_the_text, cut_all=True)
for s in seg_list:
if accepted_chars.match(s) and s not in ignore_list:
if s not in file_words.keys():
file_words展开 = [0,1]
else:
file_words展开[1] += 1
finally:
file_object2.close()
sum_2 = 0
sum_file1 = 0
sum_file2 = 0
for word in file_words.values():
sum_2 += word[0]*word[1]
sum_file1 += word[0]**2
sum_file2 += word[1]**2
rate = sum_2/(sqrt(sum_file1*sum_file2))
print 'rate: '
print rate
file_reader('a1.txt','a2.txt')
#该片段来自于http://outofmemory.cn
我们先试一下,a1.txt和a2.txt为同一个文件时结果是什么?

rate值为1,说明两篇文章主题相似度非常高
我们再来把a2.txt换成另一篇完全不相关的内容看看:
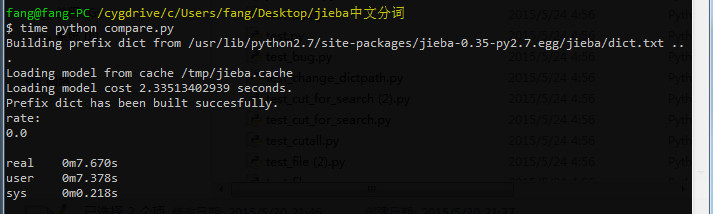
这回rate值为0,说明两篇文章主题相似度非常低。
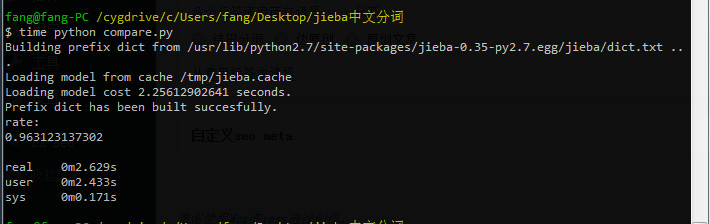
rate值为0.96,说明这两篇文章相似度非常高!可以像百度这样专业的搜索引擎,想要判断一篇文章是否是伪原创的,是多么容易.......
参考资料
2、《【百度搜索研发部】搜索背后的奥秘--浅谈语义主题计算》
文章来源:http://outofmemory.cn/code-snippet/35172/match-text-release




2016-02-04 上午10:14
[嘻嘻]你忘记了百度是大数据处理,你这两篇文章对比肯定容易,给你几万亿文章两两对比看看
2015-07-20 上午11:52
不准,两篇文章,一篇是金融,一篇是建筑,竟然相似率高达84%