- A+
2014年6月21日补充
刚在文章留言里看到有朋友指出,下面提到的这些,只能在windows系统实现,用linux系统的朋友可能没这么复杂了,因为linux直接内置这些命令的,根本不需要这个cygwin软件。我把读者默认地当成是用过cygwin的人了。在此我声明一下,如果需要进行下面所有的操作,你首先得了解什么是cygwin,以及能搞定cygwin在windows系统下的安装。
cygwin的下载及安装请看这篇百度经验文章:http://jingyan.baidu.com/article/200957619b0c30cb0621b478.html,回头我再写一个侧重于SEO工具方面的详细安装教程。
第一步:合并最近一个月的日志文件
转到日志文件存放的目录,最简单的办法是输入cd命令后,把文件夹拖进shell窗口中来:
cd /cygdrive/c/Users/fang/Desktop/wwwlog
合并最近一个月的日志文件,并输出结果到all.txt文件中:
cat *.log >all.txt

第二步:拆分出百度蜘蛛的日志
合并完日志文件,拆出百度蜘蛛日志太简单了,一条grep命令就行:
grep "Baiduspider" all.txt >bd.txt

第三步:批量提取404错误页面。
且仅提取百度蜘蛛遇到的404错误页面,其中的$17是我当前日志文件404状态码所在的分段,去重并仅保留html/php/asp三种格式的网页。
很多朋友问我这个$17值怎么来的,我贴出一段示例日志用来说明一下,每一项都是以空格隔开的,大家数一下自己的404状态码在第几段就行了,图太小看不清的话,右键在新窗口打开即可看原图:

cat bd.txt|awk '{if($17~"404")print "http://www.yaranpeixun.com"$7}'|sort|uniq|egrep "html|php|asp" >404.txt

最终效果如下:熟练的话,不到分钟就可以把最近一个月的404错误页面URL给提取到了:

上传这个404错误页面列表到你网站根目录下,然后我们就可以到百度站长平台去提交这些404错误页面了:

其实上面的所有代码,都可以写到一块儿去,我们可以通过管道命令“|”来实现:
cat *.log|grep "Baiduspider"|awk '{if($17~"404")print "http://www.yaranpeixun.com"$7}'|sort|uniq|egrep "html|php|asp" >404.txt

上面所用到的所有命令,都可以在这篇文章中得到详细的使用方法介绍:Shell分析日志常命令快速入门,请自行补脑一下。在下一篇文章当中,我将为你继续分享我在学习shell和利用shell分析日志过程中一些心得。
如果你觉得这篇文章对你有帮助,可以在下面给我留言告诉我,谢谢!:)
2014年6月27日补充
如果想再严谨一点话,可以把上面得到的404错误URL再拿来跑一遍,防止某些情况下蜘蛛在爬到这个URL时,该URL只是临时打不开的,当我们在分析的时候它已经可以打开了。下面是批量跑404URL的shell代码,点击下载源代码。
跑完1744条URL用时7分多钟。

while read line
do
curl -w "$line "%{http_code}"\n" -s -o /dev/null -I "$line" >>404url.txt
done <404.txt
跑完以后会自动生成404url.txt,结果如下所示:
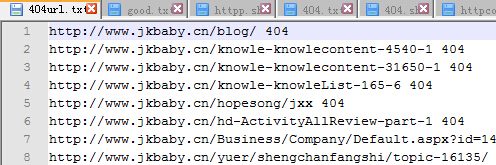
检查一批URL的HTTP状态:cat url.txt|while read line; do curl -I $line -m 5 --connect-timeout 5 -o /dev/null -s -w "$line "%{http_code}"\n"; done>ok.txt




2014-11-26 上午9:10
不错的方法,借鉴了。
2014-06-24 上午11:33
方法老师,你其实是雷锋吧!
2014-06-24 上午11:52
@Sunny 太夸张了!
太夸张了!
2014-06-21 上午12:41
可以注明一下是***in专用,linux不适用
2014-06-21 上午11:04
@游客 谢谢你的建议,我现在就在文章开头声明一下。