- A+
最近需要对聚合页面SEO做研究,为了对比分析需要记录各同行网站的关键词排名情况。
手工记录的话效率太低,样本数量也有限。
于是要把这部分工作自动化,因为自学过PHP编程,实现这个需求没问题。
但我打算使用Python,给自己一天的时间边学边写代码,用项目来驱动Python学习。
不是完全的零基础,去年看过廖雪峰的Python3教程。
但“看过”与“用过”差距真是不小,这几天仅靠Google和Stackoverflow,居然解决了一个个坑,把任务完成了。
我把整个需求和代码贴出来,作为自己的总结,也希望给大家一些参考。
获取待监测的关键词
从爱站网可以查看某个网站特定目录的关键词和排名(支持PC和移动),流量统计当然可以获取更多关键词,但是无法获取关键词指数。
比如,查看我们网站PC“产品词”页面获得关键词排名,按指数由高到低排序。http://baidurank.aizhan.com/baidu/huangye88.com/product/0/1/exp/-1/...
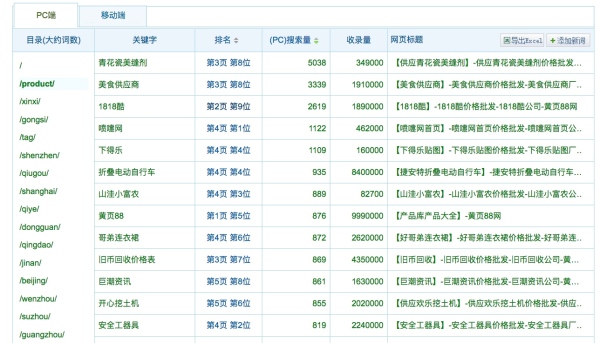
想要导出这些词,需要爱站网账号,没有可以自己写程序抓取。
代码和注释如下:
#coding:utf-8
#导入正则库
import re
#导入sys库,为了使用sys.exit()中断调试使用。
import sys
#python3中只要urllib库,没有urllib2,这里导入urllib.request用于请求页面采集
import urllib.request
#导入这个库为了对中文进行URL编码
import urllib.parse
#导入这个库为了让抓取程序暂停1秒采集,避免太快被封
import time
#这个库需要按照 pip install var_dump ,类似于php的var_dump,调试代码时使用
from var_dump import var_dump
#python的xpath类库,让采集规则支持xpath语法,降低采集难度
from lxml import etree
#定义一个方法通过URL获取页面HTML代码
def getHTML(url):
#定义请求的header,伪装请求。对于爱站来说,如果没有referer地址,无法采集正确页面。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)',
'Referer':'[百度一下,你就知道](http://www.baidu.com)'
}
# 构建一个http请求,使用自定义的headers信息
req = urllib.request.Request(url, headers = headers)
# 代码睡1秒
time.sleep(1)
# 采集信息,获得一个html代码对象
html_obj = urllib.request.urlopen(req)
# 读取html源代码为字符串,并用utf-8编码输出
html = html_obj.read().decode("utf-8")
return html
# 定义一个获得特定网站的爱站关键词的方法
def getWords(url, website):
# 根据URL获得HTML代码
source = getHTML(url)
# print(source)
# 转化为支持Xpath的DOM结构
selector = etree.HTML(source)
# 写Xpath语法,获取页面中class为word_record_w的a标签的所有文本,也就是关键词
words = selector.xpath('//a[@class="word_record_w"]/text()')
#循环把一个个词写入aizhan_word_网站域名.txt的文件中
for item in words:
print(item.strip())
# 打开文件,使用append模式写入关键词,一行一个,strip()用于去掉关键词前后的空白
with open('./aizhan_word_' + website + '.txt', 'a') as f:
f.write(item.strip() + "\n")
# 爱站最多显示50页,从第一页开始,构造各个分页的URL
for x in range(1,51):
# 为了以后能适用采集别的网站,这里单独给网站设置一个变量
website = "huangye88.com"
# 为了支持不同的目录,同理设置一个变量
dirname = "product"
# 因为x是数字,为了拼URL,需要用str(x)转化为字符串
url = "[站长工具_百度权重查询 - 爱站网](http://baidurank.aizhan.com/baidu/)"+ website +"/"+ dirname +"/0/"+ str(x) +"/exp/-1/"
# 开始采集关键词
getWords(url, website)
采集百度搜索结果页
我们已经获得了一个包含几千关键词的文本文件:
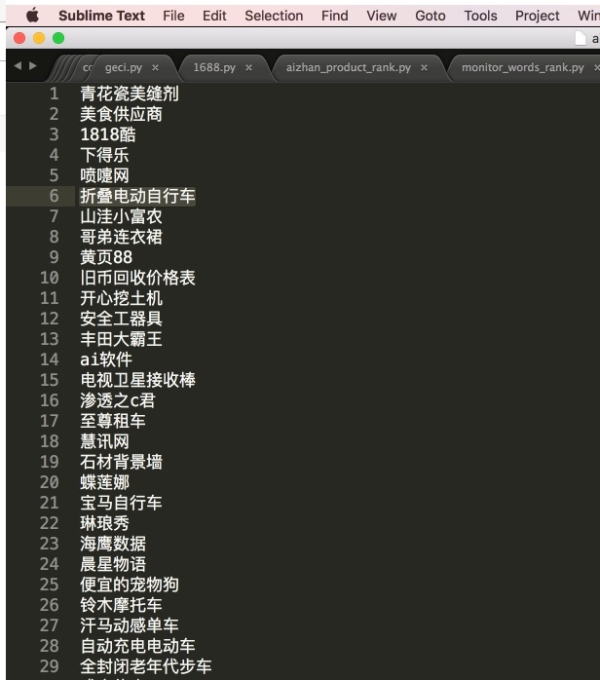
下一步需要使用这些关键词把百度前几页的搜索结果拿到,当出现下面域名时,把对应的网址、标题、排名、关键词、日期写入Mysql数据库中。
‘http://huangye88.com’‘http://hc360.com’‘http://1688.com’‘http://china.cn’‘http://makepolo.com’‘http://b2b168.com’‘http://liebiao.com’
上面域名对应B2B行业网站黄页88网、慧聪网、阿里巴巴、中国供应商、马可波罗网、八方资源网、列表网,你可以根据自己想监测的竞争对手网站调整。
代码如下:
#encoding=utf-8
import re
import sys
import urllib.request
import urllib.parse
import time
# 需要获取日期,所以导入这个库
import datetime
# 需要解析JSON文件
import json
from var_dump import var_dump
from lxml import etree
# 连接Mysql数据库,使用pymysql数据库,研究对比了几个,python3大家用这个多
import pymysql
# 定义一个根据URL获取HTML代码的方法
def getHTML(url):
req = urllib.request.Request(url)
html_obj = urllib.request.urlopen(req)
html = html_obj.read().decode("utf-8")
return html
# 定义一个获得搜索结果页面的方法
def getSERP(word):
# 把关键词做URL encoding
newword = urllib.parse.quote(word)
# 拼出来一个百度搜索结果页地址,注意下面是样例,非正式地址。
url = "[百度一下,你就知道](http://www.baidu.com/s?wd=)"+ newword +"&xxx=0&xxx=50&xxx=json"
html = getHTML(url)
# 把html源代码转化为JSON对象
html = json.loads(html)
获得一条条搜索结果记录
items = html['feed']['entry']
# 循环整个数组,index+1就是对应的排名
for index,value in enumerate(items): # 如果包含url这个属性,则读出网址、标题和排名
if 'url' in value:
item_url = value['url']
item_title = value['title']
item_rank = index + 1
# 所以希望记录的网址特征符
all_websites = ['huangye88.com', 'hc360.com', '1688.com', 'china.cn', 'makepolo.com', 'b2b168.com', 'liebiao.com']
# 今天的日期
now = datetime.datetime.now()
# 转化成年月日格式的字符串 ,比如2017-06-26
today = now.strftime('%Y-%m-%d')
# 如果URL中包含all_websites中的任意特征符则打印出来网址、标题和排名
if any(item in item_url for item in all_websites):
print(item_url)
print(item_title)
print(item_rank)
# 构造一个字典对象
line = {"title":item_title, "url":item_url, "rank":item_rank, "kw":word, "date": today}
# 写入Mysql数据库
saveIntoDB(line)
# 定义一个写入数据库的方法
def saveIntoDB(line):
# 尝试写入,避免出错直接跳出
try:
# 连接数据库的方法,记住需要加charset='utf-8' 否则terminal读取显示会有乱码
db = pymysql.connect("localhost","Mysql用户名","Mysql密码","数据库名", charset='utf8')
# 数据库操作指针
cursor = db.cursor()
# 执行写入操作
effect_row = cursor.execute("insert into b2b_kw_rank(title,url,rank,kw,date) values(%s,%s,%s,%s,%s)", (line["title"], line["url"], line["rank"], line["kw"], line["date"])) # 提交写入操作,否则不会写入
db.commit()
# 关闭数据库连接
db.close()
except:
pass
# 读取文件,一行一个
for line in open("aizhan_word.txt"):
# 去掉前后空格
word= line.strip()
# 执行获取搜索结果页的函数
getSERP(word)
数据库结构:
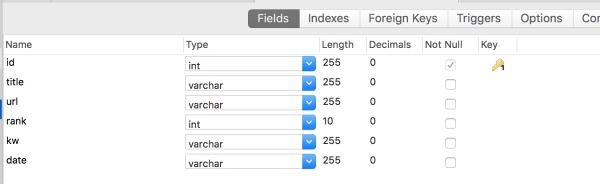
为了简化程序写法,而且搜索引擎更新没有那么频繁,所以每个URL每天只记录一条,把url和data联合做一个unique索引。

程序运行后的结果:
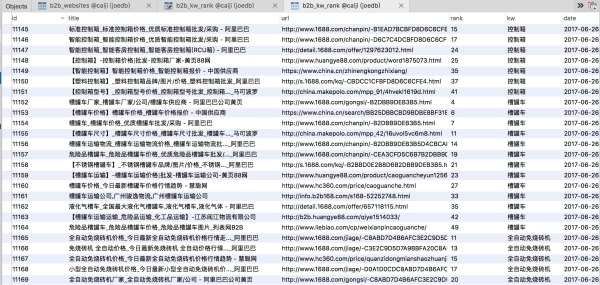
后续分析
有了数据,以后可以对这些关键词进行单独分析,监测各关键词搜索结果的排名变化情况,从而判断各个竞争对手网站的SEO效果,进一步分析页面做法。
导出了一天的数据,使用Excel做一些粗略分析:
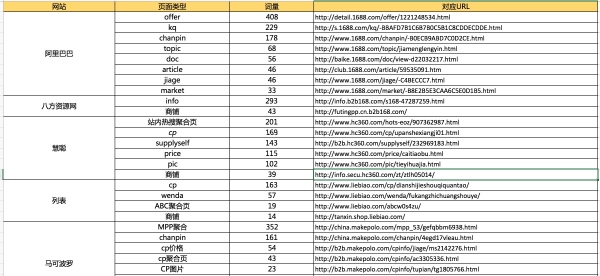
至少对于这1200多个词说,各家网站的平均排名如下:
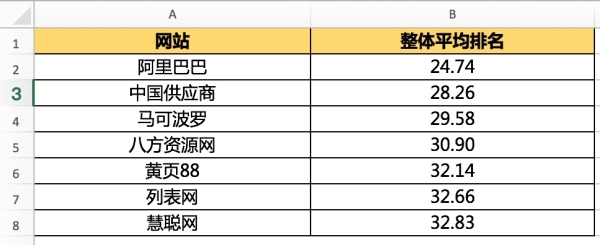
阿里巴巴是当之无愧的老大,SEO效果最好,甚至好的有些过分。
一页结果7个来自阿里巴巴,着陆页为各种聚合页面,不讲理的强!
据说阿里巴巴的聚合页面每个都有6~30个外链,外链来自于自己养的25万站群。(待考证)
各B2B网站SEO排名好的聚合页面
阿里巴巴
kq目录(229)
chanpin目录(178)
topic目录(68)
jiage目录(46)
market目录(33)
慧聪网
hots站内热搜词聚合(201)
cp目录(169)
price目录(115)
pic目录(102)
列表网
cp目录(163)
wenda目录(57)
ABC聚合页(19)
马可波罗网
MPP聚合目录(352)
chanpin目录(161)
cp价格聚合(54)
cp聚合页(43)
cp图片聚合(23)
pinpai聚合(15)
中国供应商
search目录(90)
https://www.china.cn/search/BE16AB8FBDC5DBB0DF0CAD17DB00CBDBDF5AED.html...
subject目录(17)
附录:各大B2B网站常规的聚合页做法简单介绍
1、收集整理大量长尾词。
来源可能如下:A:用户站内搜索词B:用户发布信息时填写的关键词、品牌词等C:百度搜索相关词、下拉词拓展D:采集竞争对手网站词库…
2、分析整理词库,设计着陆页
借助人工或搜索分析,把词归类,定制聚合页面。
使用关键词调用站内的信息和公司等资料,生成聚合页面。
注意:设计聚合页需要针对性的定制页面TDK规则、布局和模块规则,避免不同聚合页内容重复。
URL常见有三种做法:A、中文拼音 B、对关键词进行Dehex编码处理 C、数字ID
这三种方法各有利弊,阿里巴巴的URL方式可以对关键词方便的编码加工和反加工,不怕空格和特殊字符,这点比拼音有优势。
甚至我们还使用过中文URL,后来证明容易出各种抓取上的问题,不建议。
Dehex编码(问技术要的):
// 对关键词做dehex编码处理(PHP版本)
function encode($word){
$length = strlen($word);
$asc = '';
for($i=0; $i<$length; $i++){
$asc .= dechex(ord($word[$i]));
}
return strtoupper($asc);
}
// 对关键词做解码处理(PHP版本)
function decode($str){
$parts = str_split($str, 2);
$word = '';
foreach ($parts as $part){
$word .= chr(hexdec($part));
}
return $word;
}
3、推广聚合页面
A、提交SitemapB、在蜘蛛抓取频繁页面增加入口地址C、增加反向链接
文章来源:乔向阳的知乎专栏
