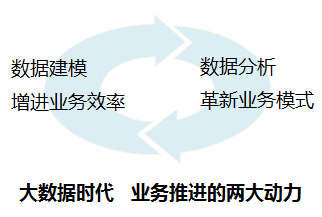
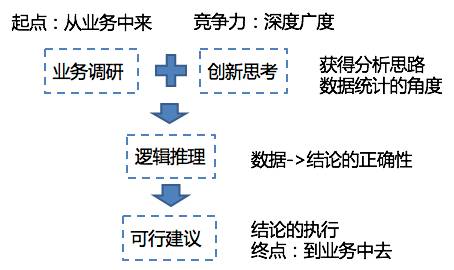
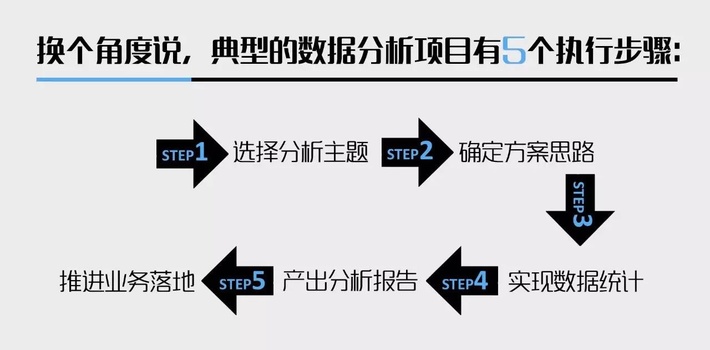
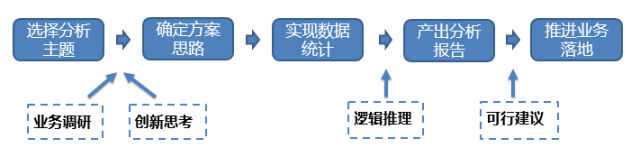
数据分析4个关键点的关系 一份优秀的分析报告,最终呈现的统计方法一定要简单清晰(make it simple),切忌喧宾夺主。如果报告的阅读者需要花80%的精力来搞清楚统计方法,而不是理解分析结论,这份报告就失败了。九枝兰:从上面的分析中,我们看到,想做好数据分析比较复杂,所以,能否请你总结下,做好数据分析最基本的的流程是什么? 毕然:我认为做好数据分析如写好诗一样,在于立意而不是技术。下面逐一展开讲解“业务调研”、“创新思考”、“逻辑推理”和“可行建议”这四个关键。
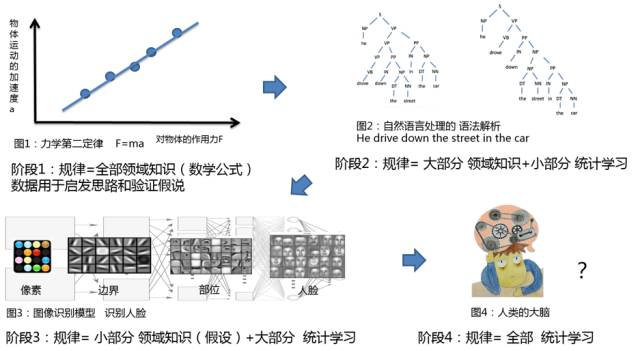
精细刻画指用很多特征来描述一种关系。因为如果收集到的样本量很少,就无法用较多的特征来细分样本。因为落到每个细分格子中的样本数过少使统计结论不置信,如“海淀区西二旗6~10岁的女童喜欢男性旅游鞋”的结论。虽然该结论很荒谬,但这种细致描述的方法还是很有价值的。市场细分意味着差异化需求,其中隐藏了巨大的商机。如果能够获取足够大的样本量,可以支撑更细致的结论,而不用担心置信性。 这是“大数据”的第一个价值:有了“大数据”,一切统计模型都变得极其个性化。 如医疗领域的场景,当医生遇到新病人时,一方面根据自己所学的理论知识进行分析,另一方面也会和以往接触过的病例进行比对。如果之前遇见过与新病人很像的病例,当时的治疗方案已经被印证效果良好,医生会给出相近的诊疗方案。但每个医生见过的病例是有限的。如果找不到完全一致的病例,就只能参考一些部分相似的病例,诊疗方案效果大概率会打折扣。这也是老中医比年轻中医受欢迎、一线城市的知名医院比小城市的医院更受欢迎的原因之一,因为前者经历过更多的病例。大数据的价值类似于收集到足够多的病例,对于每一个病人,均可以找到数量众多的相似病例,那么对新病人的病情分析和治疗方案会准确、有效得多。 很多互联网企业都在业务中使用这样细致刻画的模型,比如搜索引擎的广告点击率预估、电商网站的推荐系统等等,这些模型将一次查询或一次推荐的场景刻画的非常细致,甚至用成千上万维度的特征来描述规律(如:买了某本书并团购了某场电影票的年轻女性高概率会购买某件商品)。这种精细的刻画没有大数据的支持几乎是不可能的,没有大数据我们只能得到“女性喜欢A,男性喜好B”这样很粗略的统计规律。大样本使大特征成为可能,大特征使大样本发挥价值。——大数据时代大数据使得“统计科学”的重心发生了变化。经典统计学更多探讨“如何从抽样的个体样本推断整体数据的统计结论”;而大数据时代,讨论的主题则是“如何寻找合适的维度切分整体数据,以便更好的推断个体行为”。价值2:大数据使“智能学习”变成可能 人类基于观测数据探索世间规律,共经历了四个阶段。 基于观测数据探索规律所经历的四个阶段 (注释:阶段3中的图像图片来自于Andrew Ng的报告《Machine Learning and AI via Brain simulations》第39页)阶段1 规律=全部领域知识(用数学公式表示),数据用于启发思路和验证假说:科学家根据观察到的现象提出假说(表达规律的数学公式),然后收集实验数据来验证假说。 典型如牛顿第二定律F=ma,物体的加速度与所受外力正比,与物体质量成反比。在生活中时有体会,推动一个物体,使用的力气越大,它的加速越快;该物体越沉重(需排除摩擦力的干扰),它加速的越慢。相信大家对中学含有小车、砝码与滑轮的物理实验记忆犹新。这个阶段,数据在人类学习的过程中,主要起“启发科学家设计假说的思路”和“验证假说有效性”的作用。阶段2 规律=大部分领域知识+小部分统计学习:人类将某个领域的知识梳理清楚,留下小部分内容交给机器基于数据来学习。 典型如自然语言处理(NLP)中的语法解析,首先由人类总结出语法规则,根据语法规则解析某句话,如“he drive down the street in the car“,这句话既可以解析成“他开车穿过街道”,也可以解析成“他穿过车里的街道”,两种方式均满足语法规则)。但前者是人类在该语境中习惯的表达方法,而后者则不是。哪个解析结果更符合语境,可以交由机器解决,它通过语料库(大量资料、文献、对话的文本记录),判断前者出现(被使用)的概率更高。最终,人类总结的语法规则和机器在语法规则上建立的统计模型一起完成了语法解析的任务。阶段3 规律=小部分领域知识+大部分统计学习:机器学习越来越智能,越来越多的领域知识不再需要人类梳理和总结,而可以通过机器自动学到。 典型如近些年火热的深度学习模型,进一步减少了机器学习对领域知识的依赖。在图像处理的人脸识别问题中,通过深层次的神经网络,可以自动学习出从像素到边界、从边界到部位、再从部位到人脸的深层次图像内涵,不再依赖人类的梳理总结。但网络结构的设计和非线性变换的函数,依然需要人类基于图像处理领域的特点去设定,所以不能说全部脱离领域知识。阶段4 规律=全部统计学习。 曾看过一篇科研报道,当一个人的听觉细胞全部坏死后,部分视觉细胞开始承担听觉的功能。这说明人脑细胞的学习能力并不受领域知识结构的限制。人类从远古到现今,没有其他生命告诉人类世间的规律和道理。但我们从零开始,一代代的探索和积累,形成了对这个宇宙中各种规律的认知。如果机器有一天能够完全不带任何假设(前置的领域知识)的学习,它就真正具备人类的学习能力了。机器可以自动探索世界,代替人类做科学研究。这四个阶段的演变过程是统计学习越来越智能的过程,所需的数据量也由少变多。验证一个规律,只需要采集少量实验数据点即可。而在领域知识(假设)越来越少的情况下,统计学习则要承担更多的探索,需要的数据量也越来越多。 所以,大数据带来的第二个价值,是使“智能学习”变为可能。只有数据量足够大,机器才能减少对领域知识的依赖,更加智能的学习。 注释:使用机器学习领域的专业术语“越强大的模型,意味着越宽泛的假设空间,需要越多的数据样本,否则模型会过拟合”。 价值3:数据叠加的价值是非线性增长:1+1>2 前两种价值也可以这样理解:单一种类的数据量增多,可以捕捉更加细致的规律(关系Y-X,Y与X的可能数量增多)和更加复杂的规律(Y-X之间的关系复杂)。此外,随着数据种类的增多,信息会交织在一起,提供更丰富的内涵。 在移动互联网与可穿戴设备兴起的今天,几乎每个人的生活都会在网络上留下印记:个人数据、搜索数据、电商数据、社交数据、地图数据,如果将这些数据整合在一起,几乎可以完整的描绘一个人,他的所见所想、所需所求。 可见,在营销领域,利用大数据可以让企业主更精准的找到目标受众,而在“智能学习”、非线性增长领域也发挥着重要价值。